What’s in Store?
- This chapter introduces the NoSQL database Cassandra.
- It covers basic CRUD (Create, Read, Update, Delete) operations using CQL (Cassandra Query Language).
- The goal is to understand Cassandra’s features and operations effectively.
7.1 Apache Cassandra - An Introduction
Key Points from Introduction
- Origin: Born at Facebook, open-sourced in 2008, became a top-level Apache project in 2010.
- Foundation: Built on concepts from Amazon’s Dynamo (distributed key-value store) and Google’s BigTable (distributed storage system for structured data).
- High Availability: Designed with NO single point of failure. It uses a masterless (peer-to-peer) architecture, making it resilient to node failures, which is crucial for business-critical applications needing constant uptime.
- Scalability: Highly scalable (elastic scalability). It distributes and manages massive datasets across commodity servers (standard, inexpensive hardware). It scales out (horizontally) by adding more nodes.
Features of Cassandra (Refer Figure 7.1)
- Open Source: Freely available and community-supported.
- Distributed: Data is spread across multiple nodes (servers).
- Decentralized (Symmetric / Peer-to-Peer): All nodes in the cluster are equal; there is no master node.
- No Single Point of Failure: The decentralized nature ensures the system continues working even if some nodes fail.
- Column-Oriented: Data is stored in columns rather than rows, which can be efficient for certain types of queries. (Note: More accurately, it’s a partitioned row store, but often referred to as column-family oriented).
- Elastic Scalability: Easily scale the cluster up or down by adding or removing nodes without downtime.
- Tunable Consistency: Offers flexibility to choose the level of consistency required for reads and writes (explained later).
- Adherence to BASE: Follows the BASE (Basically Available, Soft State, Eventual Consistency) principles, prioritizing availability and partition tolerance over strict, immediate consistency (as seen in ACID databases). This is aligned with the CAP theorem.
Companies Using Cassandra
- Netflix
- Cisco
- Adobe
- eBay
- Rackspace
- (Many others)
7.2 Features of Cassandra (Detailed Explanation)
7.2.1 Peer-to-Peer Network (Refer Figure 7.2)
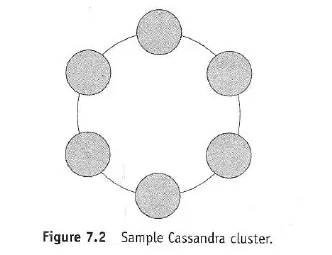
- Cassandra distributes data and load across multiple nodes in a cluster, typically using commodity hardware.
- Key Concept: All nodes are identical (homogeneous) and play the same roles. There’s no master node coordinating everything, eliminating bottlenecks and single points of failure.
- Fault Tolerance: If a node fails, the cluster continues to operate, possibly with graceful degradation (reduced performance/capacity) but without complete failure.
- Data Distribution: Data is distributed automatically across all nodes in the cluster.
- Node Communication: Nodes exchange information about themselves and other nodes (more on this under Gossip).
- Write Path Overview:
- When data is written, it’s first written sequentially to an on-disk Commit Log (for durability, ensures data isn’t lost if the node crashes).
- Then, data is written to an in-memory structure called a Memtable.
- Writes are considered successful once written to the commit log and Memtable.
- When the Memtable becomes full, its contents are flushed to disk as an SSTable (Sorted String Table). SSTables are immutable (cannot be changed once written).
(Figure 7.2 shows a ring architecture, typical of Cassandra clusters, where nodes are conceptually arranged in a circle.)
7.2.2 Gossip and Failure Detection (Refer Figure 7.3)
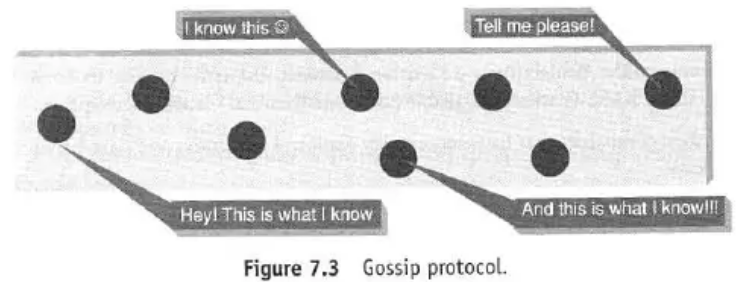
- Gossip Protocol: A peer-to-peer communication protocol used for discovering the location and state information of other nodes in the cluster.
- How it Works: Each node periodically communicates (“gossips”) with a few other randomly chosen nodes, exchanging state information about itself and other nodes it knows about. This information propagates throughout the cluster efficiently.
- Purpose: Cluster membership, node status detection (up/down), and information sharing. It’s robust and scales well.
- Failure Detection: Gossip helps detect nodes that are down or unresponsive.
7.2.3 Partitioner
- Purpose: Determines how data is distributed across the nodes in the cluster.
- Mechanism: It uses a hash function to compute a token from the partition key of a row (typically derived from the primary key).
- Function: This token determines which node is responsible for storing the first copy (replica) of that row. It essentially maps data to nodes.
7.2.4 Replication Factor (RF)
- Definition: Determines the number of copies (replicas) of each row that will be stored across different nodes in the cluster.
- Example: An RF of
3means each row will be stored on three different nodes. - Purpose: Provides fault tolerance and data redundancy. If one node holding a replica fails, the data is still available on other replicas.
- Setting: Should ideally be greater than one for production systems.
Replication Strategies
Determines how replicas are placed across the nodes.
SimpleStrategy:- Used for single data center deployments.
- Places the first replica on the node determined by the partitioner.
- Subsequent replicas are placed on the next nodes clockwise in the ring.
- Limitation: Doesn’t consider network topology (like racks), so replicas might end up on the same physical rack.
NetworkTopologyStrategy:- Preferred strategy for most deployments, especially multi-datacenter or rack-aware setups.
- Allows specifying the RF for each data center independently.
- Tries to place replicas on different racks within a data center to minimize correlated failures (e.g., if a rack loses power).
- More complex but provides better fault tolerance.
7.2.5 Anti-Entropy and Read Repair
- Context: Since data is replicated and updates happen concurrently, replicas might temporarily become inconsistent.
- Anti-Entropy: A background process in Cassandra that compares replicas of data and repairs any inconsistencies found, ensuring replicas eventually converge to the same state. It uses Merkle Trees (not detailed in the text) for efficient comparison.
- Read Repair: An inconsistency repair mechanism triggered during a read request.
- When a read query requires checking multiple replicas (based on the read consistency level), Cassandra compares the data returned from those replicas.
- If inconsistencies are detected, Cassandra sends updates to the nodes with outdated data (in the background, usually after returning the most recent data to the client).
- Helps keep data consistent proactively.
7.2.6 Writes in Cassandra
- Process:
- A client sends a write request to any node (which acts as the coordinator for that request).
- The coordinator uses the Partitioner to identify the nodes responsible for storing the replicas of that data.
- The coordinator forwards the write request to all replica nodes.
- Each replica node writes the data first to its Commit Log (on disk, for durability) and then to its Memtable (in memory, for fast writes).
- A replica node acknowledges success back to the coordinator once the write hits the commit log and memtable.
- The coordinator waits for acknowledgements from a specific number of replica nodes (determined by the Write Consistency Level) before confirming success to the client.
- Flushing: Periodically, or when a Memtable is full, its contents are sorted and written to disk as an immutable SSTable. Flushing is a non-blocking operation.
7.2.7 Hinted Handoffs
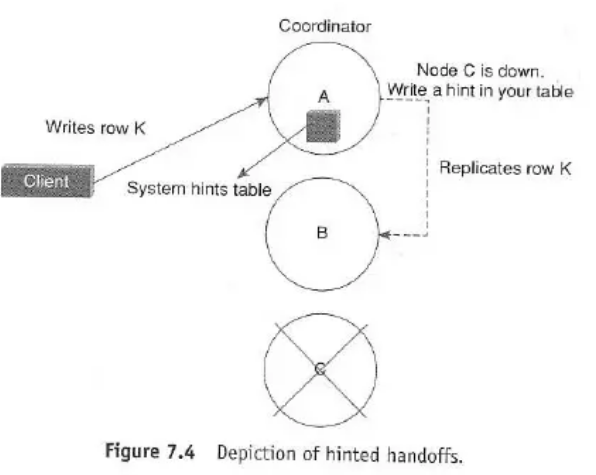
- Purpose: To handle writes when a replica node is temporarily unavailable (down or unresponsive).
- Mechanism:
- Assume Node C is down, and a write arrives for data that should be replicated on Node C.
- The coordinator node (e.g., Node A) detects Node C is down.
- Instead of failing the write (if consistency allows), Node A stores the data locally along with a “hint” indicating that the data actually belongs to Node C. The hint contains info like replica location, version metadata, and the actual data.
- Node A periodically checks if Node C is back online.
- When Node C recovers, Node A forwards the stored (hinted) write to Node C.
- Benefit: Improves write availability during temporary node outages. It’s a temporary measure; hints are typically stored for a limited time (e.g., a few hours).
7.2.8 Tunable Consistency
- Concept: Cassandra allows developers to choose the consistency level for each read or write operation, providing a trade-off between consistency, availability, and latency.
- Consistency Spectrum: Can range from strong consistency (all replicas involved) to eventual consistency (data will become consistent over time, but reads might get stale data).
Strong vs. Eventual Consistency
- Strong Consistency: Ensures that a read always reflects the latest completed write. Requires coordination among replicas, potentially increasing latency and reducing availability if nodes are down.
- Achieved in Cassandra by configuring read and write consistency levels such that they overlap sufficiently (e.g., , see below).
- Eventual Consistency: If no new updates are made, eventually all replicas will converge to the latest value. Reads might return older data temporarily. Prioritizes availability and low latency.
7.2.8.1 Read Consistency (Refer Table 7.1)
Defines how many replica nodes must respond to a read request before the coordinator returns a result to the client.
ONE: Returns data from the closest replica. Fastest, least consistent.QUORUM: Returns data after a quorum of replicas respond. Provides a balance between consistency and performance.LOCAL_QUORUM: Returns data after a quorum of replicas in the same data center as the coordinator respond. Avoids cross-DC latency.EACH_QUORUM: Returns data after a quorum of replicas in each data center respond. Stronger consistency across DCs.ALL: Returns data after all replicas respond. Strongest consistency, but lowest availability (fails if any replica node is down).
(Table 7.1 lists these levels and their descriptions.)
7.2.8.2 Write Consistency (Refer Table 7.2)
Defines how many replica nodes must successfully acknowledge a write (commit log + memtable) before the coordinator reports success to the client.
ANY(Not listed in table but exists): Ensures the write has been written to at least one node (could be the coordinator storing a hint if all replicas are down). Lowest durability guarantee.ONE: Ensures the write hit the commit log and memtable of at least one replica node.TWO: Ensures write succeeded on at least two replica nodes.THREE: Ensures write succeeded on at least three replica nodes.QUORUM: Ensures write succeeded on a quorum of replica nodes. Common choice.LOCAL_QUORUM: Ensures write succeeded on a quorum of nodes in the coordinator’s local data center.EACH_QUORUM: Ensures write succeeded on a quorum of nodes in all data centers.ALL: Ensures write succeeded on all replica nodes in the cluster. Highest consistency/durability, lowest availability.LOCAL_ONE: Ensures write succeeded on at least one replica node in the local data center. Used for asynchronous cross-DC replication.
(Table 7.2 lists these levels and their descriptions.)
Achieving Strong Consistency: A common practice is to use QUORUM for both reads and writes. If the Replication Factor is RF, the number of nodes for read quorum is and for write quorum is . The condition ensures that the set of nodes read always overlaps with the set of nodes written, guaranteeing that at least one node read has the latest write.