Traditional Database Applications: Often involved data-processing tasks (e.g., banking, payroll) with relatively simple data types, well-suited for the relational data model.
Limitations of Relational Model: As databases were applied to wider applications (e.g., Computer-Aided Design (CAD), Geographical Information Systems (GIS)), limitations of the relational model in handling complex data became an obstacle.
Solution: Object-Based Databases: Introduced to handle complex data types more effectively.
22.1 Overview
Obstacle 1: Limited Relational Type System
Problem: The relational model historically supported only a limited set of simple data types. Complex application domains require correspondingly complex data types.
Examples of Needed Complex Types: Nested record structures, multivalued attributes, inheritance (features often found in programming languages and supported conceptually in E-R/Extended E-R models but needing translation to simpler SQL types).
Solution Concept: Object-Relational Data Model
Definition: Extends the relational data model.
Features: Provides a richer type system including complex data types and object orientation.
Query Language Extension: Relational query languages (especially SQL) needed corresponding extensions.
Goal: Preserve relational foundations (especially declarative access to data) while increasing modeling power.
Object-Relational Database Systems: Database systems based on the object-relational model. Provide a migration path for users of relational databases needing object-oriented features.
Obstacle 2: Impedance Mismatch (Database vs. Programming Language)
Problem: Difficulty accessing database data efficiently and naturally from programs written in languages like C++ or Java. Extending the database type system alone wasn’t a complete solution.
Challenges:
Type System Differences: Mismatches between database types and programming language types complicate data storage and retrieval, requiring minimization.
Language Differences: Using a different language (SQL) for database access within a host programming language increases programmer effort.
Desire: For many applications, it’s desirable to have database access integrated seamlessly into the programming language, using its native type system and avoiding intermediate languages like SQL.
Two Main Approaches Addressed in this Chapter:
Object-Oriented Database System (OODBMS):
Natively supports an object-oriented type system.
Allows direct data access from an object-oriented programming language using the language’s native type system.
Object-Relational Mapping (ORM):
Automatically converts data between the programming language’s native type system and a relational representation (and vice versa).
Conversion is specified using an object-relational mapping.
Chapter Goal: Provide an introduction to both object-relational and object-oriented approaches and discuss criteria for choosing between them.
22.2 Complex Data Types
Traditional Data Types: Conceptually simple, often small records with atomic fields (indivisible units, satisfying First Normal Form - 1NF). Few record types.
Demand for Complex Types: Modern applications require more complex structures.
Example: Addresses:
Treating as atomic string hides structure (street, city, state, postal_code).
Breaking into atomic components complicates queries (mentioning each field).
Better: Structured type address with subparts street_address, city, state, postal_code.
Example: Multivalued Attributes (from E-R Model):
Natural for things like phone numbers (multiple per person).
Normalization alternative (creating a new relation) can be expensive and artificial.
Benefits of Complex Types: Allow direct representation of E-R concepts (composite attributes, multivalued attributes, generalization/specialization) without complex translation to the basic relational model.
Revisiting First Normal Form (1NF): Defined in Chapter 8, requires all attributes to have atomic domains.
Limitations of 1NF Assumption: Not all applications are best modeled by 1NF relations. Users might view data as objects/entities requiring multiple records, desiring a one-to-one correspondence between their intuition and database items.
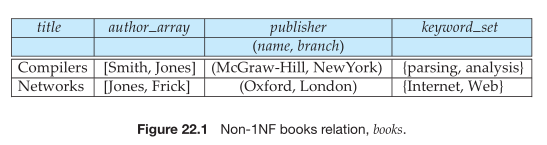
Example: Library Book Database (Non-1NF)
Information per book: Title, List of Authors, Publisher, Set of Keywords.
Nnonatomic Domains:
Authors: A list/array. Need to query for books by a specific author (e.g., ‘Jones’), implying interest in subparts. Domain is non-atomic.
Keywords: A set. Need to retrieve books based on keyword presence. Domain is non-atomic.
Publisher: Not set-valued, but can be viewed as structured with subfields name and branch. Domain is non-atomic.
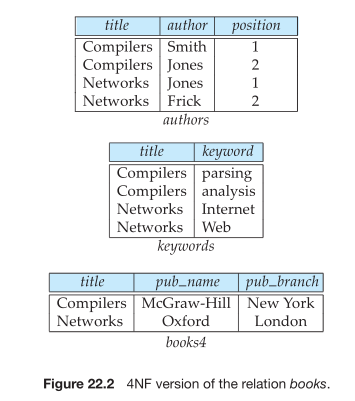
Normalization Alternative (4NF Example)
Assumption: title uniquely identifies a book (simplification, real world uses ISBN).
Schema (Primary Keys underlined):
authors(title, author, position)
keywords(title, keyword)
books4(title, pub_name, pub_branch)
This schema satisfies Fourth Normal Form (4NF).
Trade-offs: Non-1NF vs. Normalized
Non-1NF: Often easier to understand, closer to user’s mental model. Many query types become simpler (avoiding joins).
Normalized (1NF/4NF): Required for traditional relational models. Avoids certain types of redundancy. May be better in some situations (e.g., representing many-to-many relationships like takes(student, section)).
Conclusion: The ability to use complex types (sets, arrays, structures) is useful but should be applied carefully.
22.3 Structured Types and Inheritance in SQL
22.3.1 Structured Types
Purpose: Allow direct representation of composite attributes from E-R designs.
Definition Syntax:CREATE TYPE TypeName AS (attribute1 datatype1, attribute2 datatype2, ...) [FINAL | NOT FINAL];
Example: Name
CREATE TYPE Name AS (firstname VARCHAR(20), lastname VARCHAR(20))FINAL;
Example: Address
CREATE TYPE Address AS (street VARCHAR(20), city VARCHAR(20), zipcode VARCHAR(9))NOT FINAL;
These are called user-defined types (UDTs) in SQL.
FINAL vs NOT FINAL: Controls whether subtypes can be created from this type. Name cannot have subtypes; Address can. (Related to inheritance, Section 22.3.2).
Using Structured Types in Tables:
As Attribute Types: Declare an attribute to be of a UDT.
CREATE TABLE person ( name Name, address Address, dateOfBirth DATE);
Accessing Components: Use dot notation. Example: name.firstname returns the first name component. Accessing name returns the whole Name structure.
Tables of User-Defined Types: A table where each row is an instance of a UDT.
Type Definition:
CREATE TYPE PersonType AS ( name Name, address Address, dateOfBirth DATE) NOT FINAL;
Table Creation:
CREATE TABLE person OF PersonType;
(Footnote 4: Potential name conflict between type Name and attribute name in case-insensitive systems).
Unnamed Row Types: Alternative way to define composite attributes inline.
CREATE TABLE person_r ( name ROW (firstname VARCHAR(20), lastname VARCHAR(20)), address ROW (street VARCHAR(20), city VARCHAR(20), zipcode VARCHAR(9)), dateOfBirth DATE);
Equivalence: Similar to using named UDTs, but the types are unnamed. Table rows also have an unnamed type.
Accessing Components: Still use dot notation. Example query:
SELECT name.lastname, address.cityFROM person;
Methods in Structured Types: UDTs can have associated methods (functions).
Declaration (within CREATE TYPE):
CREATE TYPE PersonType AS ( name Name, address Address, dateOfBirth DATE) NOT FINALMETHOD ageOnDate(onDate DATE) RETURNS INTERVAL YEAR;
Definition (separate):
CREATE INSTANCE METHOD ageOnDate (onDate DATE) RETURNS INTERVAL YEAR FOR PersonTypeBEGIN RETURN onDate - SELF.dateOfBirth;END;
FOR PersonType: Specifies the type the method belongs to.
INSTANCE: Indicates the method operates on an instance of the type.
SELF: Variable referring to the specific PersonType instance the method is invoked on.
Body can contain procedural SQL statements (Section 5.2). Methods can update instance attributes.
Invocation: Call method on instances.
SELECT name.lastname, ageOnDate(current_date)FROM person; -- Assuming person is of type PersonType
Constructor Functions (SQL:1999): Used to create values of structured types.
Implicit Constructor: By default, every UDT has a no-argument constructor setting attributes to defaults.
Explicit Constructor: A function with the same name as the UDT.
Declaration Example (Name):
CREATE FUNCTION Name (firstname VARCHAR(20), lastname VARCHAR(20)) RETURNS NameBEGIN SET SELF.firstname = firstname; SET SELF.lastname = lastname; -- Note: Depending on SQL dialect, RETURN SELF might be neededEND;
Can have multiple constructors (must differ in argument number/types).
Invocation: Use NEW TypeName(...). Example: NEW Name('John', 'Smith').
Row Value Constructor: For row types or simple UDTs, list attributes in parentheses. Example: ('Ted', 'Codd') for the name ROW(...) type.
Example INSERT using Constructors:
INSERT INTO Person -- Assumes Person table has columns matching PersonTypeVALUES ( NEW Name('John', 'Smith'), NEW Address('20 Main St', 'New York', '11001'), DATE '1960-8-22');
22.3.2 Type Inheritance
Concept: Allows defining new types (subtypes) based on existing types (supertypes), inheriting attributes and methods.
Example Base Type:
CREATE TYPE Person ( name VARCHAR(20), address VARCHAR(20)); -- Assuming NOT FINAL implicitly or explicitly
Defining Subtypes: Use the UNDER keyword.
Syntax:CREATE TYPE SubtypeName UNDER SupertypeName (...) [FINAL | NOT FINAL];
Example: Student
CREATE TYPE Student UNDER Person ( degree VARCHAR(20), department VARCHAR(20));
Example: Teacher
CREATE TYPE Teacher UNDER Person ( salary INTEGER, department VARCHAR(20));
Student and Teacher inherit name and address from Person.
Person is a supertype of Student and Teacher.
Student and Teacher are subtypes of Person.
Inheritance Scope: Attributes and methods are inherited.
Method Overriding: A subtype can redefine an inherited method. Use OVERRIDING METHOD keyword in the method declaration within the subtype.
FINAL / NOT FINAL Revisited:FINAL prevents a type from being used as a supertype. NOT FINAL allows it.
Multiple Inheritance: A type inheriting from multiple supertypes.
Concept: Useful for modeling entities belonging to multiple categories simultaneously (e.g., Teaching Assistant is both Student and Teacher).
SQL Standard:Does NOT support multiple inheritance. (Discussed conceptually).
Conceptual Syntax:CREATE TYPE TypeName UNDER SuperType1, SuperType2 ...;
Example: TeachingAssistant (Conceptual)
-- Conceptual Example - Not Standard SQLCREATE TYPE TeachingAssistant UNDER Student, Teacher;
Attribute Naming Conflicts: Arise if multiple supertypes define attributes with the same name (e.g., department in Student and Teacher).
If inherited from a common ancestor (e.g., name, address from Person), there’s no conflict.
If defined independently, conflict occurs.
Conflict Resolution (Conceptual): Use renaming with AS clause in the UNDER clause.
-- Conceptual Example - Renaming for Conflict ResolutionCREATE TYPE TeachingAssistant UNDER Student WITH (department AS student_dept), Teacher WITH (department AS teacher_dept);
Most-Specific Type:
In SQL (and similar languages), each value (object instance) must have exactly one most-specific type assigned at creation.
An object is also associated with all supertypes of its most-specific type via inheritance.
Example: If an object’s most-specific type is Student, it is also of type Person.
SQL Limitation: An entity cannot have both Student and Teacher as its type unless there is a common subtype (like TeachingAssistant) that is its most-specific type. This is further constrained by SQL’s lack of multiple inheritance.
22.4 Table Inheritance
Concept: Corresponds to the E-R notion of specialization/generalization hierarchies applied to tables. Allows creating tables (subtables) based on existing tables (supertables).
Prerequisite: Assumes corresponding type hierarchy exists (e.g., Student type under Person type).
Supertable Definition Example:
CREATE TABLE people OF Person;
Defining Subtables: Use UNDER keyword in CREATE TABLE.
Syntax:CREATE TABLE SubtableName OF SubtypeName UNDER SupertableName;
Examples:
CREATE TABLE students OF Student UNDER people;CREATE TABLE teachers OF Teacher UNDER people;
Inheritance Implications:
Type: The type of the subtable (Student, Teacher) must be a subtype of the supertable’s type (Person).
Attributes: All attributes from the supertable (people) are implicitly present in the subtables (students, teachers).
Tuple Presence: Every tuple inserted into a subtable (students or teachers) is implicitly present in the supertable (people). Queries on the supertable will find tuples from the supertable and all its subtables.
Attribute Access: When querying the supertable (people), only attributes defined for people (i.e., attributes of Person type) can be accessed, even for tuples originating from subtables.
ONLY Keyword: Used to restrict operations to only the specified table, excluding its subtables.
Querying:SELECT * FROM ONLY people; (Finds only tuples inserted directly into people, not those from students or teachers).
DELETE / UPDATE:
Without ONLY: DELETE FROM people WHERE P; deletes tuples matching P from people AND ALSO corresponding tuples originally inserted into students and teachers.
With ONLY: DELETE FROM ONLY people WHERE P; deletes tuples matching P only if they were inserted directly into people. Tuples inserted into subtables are unaffected, even if they match P, and will still appear in subsequent queries on the supertable people.
Multiple Table Inheritance:
Concept: A table can be declared UNDER multiple supertables (parallels multiple type inheritance).
SQL Standard:Does NOT support multiple inheritance for tables.
Conceptual Example:
-- Conceptual Example - Not Standard SQLCREATE TABLE teaching_assistants OF TeachingAssistant UNDER students, teachers;
Implication (Conceptual): Tuples in teaching_assistants would implicitly be present in students, teachers, and people.
Consistency Requirements for Subtables (SQL Standard):
Tuple Correspondence: Each tuple in the supertable can correspond to at most one tuple in each of its immediate subtables. (Prevents having two students tuples for the same person).
Single Origin: All tuples corresponding to each other (representing the same entity across the hierarchy) must be derived from one single tuple insertion (into one specific table in the hierarchy).
Crucial Implication: This constraint prevents modeling overlapping specializations directly using SQL table inheritance. A tuple cannot originate from people and later also be represented in students and teachers independently. It must be inserted into students (implicitly in people) OR teachers (implicitly in people) OR (if multiple inheritance were allowed) into a common subtable like teaching_assistants. It prevents a person tuple from corresponding simultaneously to a separate students tuple and a separate teachers tuple unless via a common subtable.
Modeling Overlapping Specializations without Inheritance:
Use the standard relational approach described in Section 7.8.6.1.
Create separate tables: people, students, teachers.
students and teachers tables contain the primary key of people (as a foreign key) and attributes specific to students/teachers.
Requires explicit joins to retrieve full information and referential integrity constraints.
UNDER Privilege: SQL defines a privilege required to create a subtype or subtable under another type or table (similar rationale to REFERENCES privilege).
22.5 Array and Multiset Types in SQL
Collection Types Supported:
Arrays: Ordered collection. Elements accessed by position. Added in SQL:1999.
Multisets: Unordered collection where an element can appear multiple times (like a bag). Added in SQL:2003.
Sets (Conceptual): Unordered collection where each element appears at most once. Multisets are more general.
Usage Example: Book Information
Store authors as an ARRAY (order often matters).
Store keywords as a MULTISET (order usually doesn’t matter, duplicates might be okay or filtered later).
Definition Example:
-- Define a structured type for publisher firstCREATE TYPE Publisher AS ( name VARCHAR(20), branch VARCHAR(20));-- Define the Book type with collection attributesCREATE TYPE Book AS ( title VARCHAR(20), author_array VARCHAR(20) ARRAY[10], -- Array of up to 10 author names pub_date DATE, publisher Publisher, -- Structured type attribute keyword_set VARCHAR(20) MULTISET -- Multiset of keywords);-- Create a table of booksCREATE TABLE books OF Book;
Mapping E-R Multivalued Attributes: Can generally be mapped to MULTISET attributes in SQL. Use ARRAY if ordering is important.
Example Tuple Value (conceptual):
('Compilers', ARRAY['Smith', 'Jones'], NEW Publisher('McGraw-Hill', 'New York'), MULTISET['parsing', 'analysis'])(Requires an explicit constructor for Publisher to be defined, see 22.3.1)
Inserting Collection Values:
INSERT INTO booksVALUES ('Compilers', ARRAY['Smith', 'Jones'], NEW Publisher('McGraw-Hill', 'New York'), -- Assumes constructor exists MULTISET['parsing', 'analysis']);
Accessing Array Elements: Use array index (1-based typically in SQL).
Example: author_array[1] accesses the first author.
22.5.2 Querying Collection-Valued Attributes
Collections in FROM Clause: An expression evaluating to a collection can often be used where a table name is expected, typically via UNNEST.
UNNEST Operator: Converts a collection into a table (unnesting or flattening).
In WHERE Clause (Membership Test):
SELECT titleFROM booksWHERE 'database' IN (UNNEST(keyword_set));
(Note: Some SQL dialects might allow WHERE 'database' = ANY (keyword_set) or similar syntax)
In FROM Clause (Flattening): Creates a row for each element in the collection, often correlated with the outer table.
-- Get pairs of (title, author_name)SELECT B.title, A.authorFROM books AS B, UNNEST(B.author_array) AS A(author);
B iterates through books. For each book B, UNNEST(B.author_array) generates rows for each author. A(author) names the resulting single-column table A and its column author.
UNNEST WITH ORDINALITY: Used with arrays to get the element’s position (index).
-- Get (title, author_name, position) - Reconstructs the normalized 'authors' relationSELECT B.title, A.author, A.positionFROM books AS B, UNNEST(B.author_array) WITH ORDINALITY AS A(author, position);
Generates an extra column (position) containing the array index.
Simple Array Element Access (Limited Use Case):
-- If known there are exactly 3 authorsSELECT author_array[1], author_array[2], author_array[3]FROM booksWHERE title = 'Database System Concepts';
22.5.3 Nesting and Unnesting
Unnesting:
Definition: Transforming a relation with collection-valued attributes into a “flatter” relation (typically 1NF) without collections.
Mechanism: Use UNNEST in the FROM clause for each collection to be flattened.
Example (Flattening books completely):
SELECT B.title, A.author, B.publisher.name AS pub_name, B.publisher.branch AS pub_branch, K.keywordFROM books AS B, UNNEST(B.author_array) AS A(author), UNNEST(B.keyword_set) AS K(keyword);
Figure 22.3 flat_books: Shows the resulting 1NF relation from the sample books data after unnesting both author_array and keyword_set.
Nesting:
Definition: The reverse process: transforming a 1NF relation into a nested relation with collection-valued attributes.
Mechanism 1: COLLECT Aggregate Function:
Used with GROUP BY. Returns a multiset of values within each group.
Example (Nesting keyword):
SELECT title, author, Publisher(pub_name, pub_branch) AS publisher, COLLECT(keyword) AS keyword_setFROM flat_books -- Assumes flat_books from Fig 22.3 and Publisher constructorGROUP BY title, author, pub_name, pub_branch; -- Group by non-collection attributes
Figure 22.4: Shows the result of this query, partially nested.
Example (Nesting author and keyword):
SELECT title, COLLECT(author) AS author_set, -- Becomes a multiset, not array Publisher(pub_name, pub_branch) AS publisher, COLLECT(keyword) AS keyword_setFROM flat_booksGROUP BY title, pub_name, pub_branch;
Mechanism 2: Subqueries in SELECT Clause:
Use ARRAY(SELECT ...) or MULTISET(SELECT ...) to construct collections.
Correlate the subquery with the outer query.
Advantage: Allows ORDER BY within the subquery for ARRAY creation.
Example (Reconstructing original books from normalized tables):
SELECT B.title, ARRAY( SELECT author FROM authors AS A WHERE A.title = B.title ORDER BY A.position ) AS author_array, Publisher(B.pub_name, B.pub_branch) AS publisher, -- Assumes constructor MULTISET( SELECT keyword FROM keywords AS K WHERE K.title = B.title ) AS keyword_setFROM books4 AS B; -- Using the normalized 4NF table
Other Multiset Operators (SQL:2003):
SET(M): Returns a duplicate-free version (a set) of multiset M.
INTERSECTION: Aggregate function returning the intersection of all multisets in a group.
FUSION: Aggregate function returning the union of all multisets in a group.
SUBMULTISET: Predicate to check if one multiset is contained within another.
Updating Collections: SQL standard generally lacks ways to modify collections in place (e.g., add/remove one element). Updates usually involve assigning a completely new collection value (e.g., SET A = (A EXCEPT ALL MULTISET[v]) to delete value v).
22.6 Object-Identity and Reference Types in SQL
Concept: Object-oriented languages allow referring to objects. SQL provides reference types to reference tuples (objects) in tables.
Reference Type Syntax:REF(TypeName) - Represents a reference to a tuple whose type is TypeName.
SCOPE Clause:
Purpose: Restricts a reference attribute to point only to tuples within a specific table. Makes references behave somewhat like foreign keys.
Syntax:REF(TypeName) SCOPE TableName
Mandatory: Scope is mandatory in SQL.
Declaration Location: Can be part of the type definition or added in the CREATE TABLE statement.
Example Type/Table Definition:
CREATE TYPE Department ( name VARCHAR(20), head REF(Person) SCOPE people -- head references a Person tuple in the 'people' table);CREATE TABLE departments OF Department;-- Alternative: Scope defined in CREATE TABLE-- CREATE TYPE Department (name VARCHAR(20), head REF(Person));-- CREATE TABLE departments OF Department (head WITH OPTIONS SCOPE people);
Self-Referential Attribute (Object Identifier - OID): The table being referenced must have a designated attribute to store the unique identifier (OID) of each tuple.
Declaration: Added to the CREATE TABLE statement of the referenced table using REF IS ....
Types of Generation:
System Generated: Database automatically generates unique IDs.
CREATE TABLE people OF Person REF IS person_id SYSTEM GENERATED; -- person_id is an attribute name
User Generated: Application provides the unique identifier value during insertion. Requires specifying the ID type via REF USING.
CREATE TYPE Person (name VARCHAR(20), address VARCHAR(20)) REF USING VARCHAR(20);CREATE TABLE people OF Person REF IS person_id USER GENERATED;
Values must be unique across the table and its hierarchy.
Derived: Use existing primary key values as the identifier. Type definition needs REF FROM. Table definition uses DERIVED.
CREATE TYPE Person (name VARCHAR(20) PRIMARY KEY, address VARCHAR(20)) REF FROM(name);CREATE TABLE people OF Person REF IS person_id DERIVED; -- person_id still needed syntactically
Initializing and Using References:
Getting the Identifier: Need the OID (the value of the REF IS attribute) of the tuple to be referenced. Obtain it via a query.
Initializing (System Generated Example): Often a two-step process.
-- 1. Insert department with NULL referenceINSERT INTO departments VALUES ('CS', NULL);-- 2. Update with the reference OID obtained via subqueryUPDATE departmentsSET head = (SELECT p.person_id FROM people AS p WHERE name = 'John')WHERE name = 'CS';
Initializing (User Generated Example): Provide the known ID directly.
-- Insert the referenced person first (providing the ID)INSERT INTO people (person_id, name, address) VALUES ('01284567', 'John', '23 Coyote Run');-- Insert department using the known IDINSERT INTO departments VALUES ('CS', '01284567');
Initializing (Derived Example): Use the primary key value directly.
-- Assuming name is PK and used for derived REF-- Insert person firstINSERT INTO people (name, address) VALUES ('John', '23 Coyote Run');-- Insert department using the PK valueINSERT INTO departments VALUES ('CS', 'John');
Arrow Operator (->): Used in SQL:1999. Forms path expressions.
SELECT head->name, head->addressFROM departments;
head->name accesses the name attribute of the Person tuple referenced by head.
Benefit: Hides the explicit join needed in a pure relational model (where head would be a foreign key). Simplifies queries.
DEREF() Function: Returns the actual tuple pointed to by the reference. Attributes are then accessed using dot notation.
SELECT DEREF(head).nameFROM departments;
22.7 Implementing O-R Features
Foundation: Object-relational database systems (ORDBMs) are typically extensions of existing relational database systems (RDBMS).
Goal: Minimize changes to the core storage system code (relation storage, indexing).
Approach: Translate the complex data types and features of the object-relational model to the simpler type system of the underlying relational storage manager.
Translation Parallels: Techniques are similar to those used for converting E-R models to relational tables (Section 7.6):
Multivalued Attributes (E-R) → Multisets (O-R) → Separate Table (Relational Storage): Often stored in a separate table linked by foreign key, similar to 4NF.
Composite Attributes (E-R) → Structured Types (O-R) → Multiple Columns (Relational Storage): Each component of the structure becomes a separate column in the base table.
ISA Hierarchies (E-R) → Table Inheritance (O-R) → Relational Storage Options: See below.
Storage Strategies for O-R Features:
Subtables (Table Inheritance):
PK + Local Attributes: Each subtable stores only its primary key (possibly inherited) and locally defined attributes. Inherited attributes (other than PK) are retrieved via join with the supertable(s). Efficient space-wise, requires joins for full object retrieval.
All Attributes: Each table stores its primary key, locally defined attributes, AND all inherited attributes. Insertion happens only in the most-specific table. Faster access (no joins needed). Potential issues: replication if multiple inheritance/overlapping types were allowed; complexity in translating foreign keys referencing supertables. Might require supertables to be views.
Collection Types (Arrays, Multisets):
Direct Storage: Stored internally using specialized structures (e.g., LOBs, dedicated collection storage).
Normalized Representation: Stored in a separate auxiliary table, linked back to the main tuple via foreign key (similar to 4NF). Requires extra join/grouping cost during retrieval but potentially easier to implement using existing relational mechanisms.
Application Program Interface (API) Support:
ODBC/JDBC Extensions: Provide functions to handle structured types.
JDBC Example:getObject() method (similar to getString()) returns a Java Struct object representing the UDT. Components can be extracted from the Struct.
Class Mapping: Possible to associate a Java class with an SQL UDT, allowing JDBC to perform automatic conversion between them.
22.8 Persistent Programming Languages
Persistence: Data that continues to exist even after the program that created it terminates. (e.g., database relations, tuples).
Traditional Programming Languages: Directly manipulate only files as persistent data. Other variables are transient.
Database Access Requirement: Real-world applications need both database manipulation (e.g., SQL) and a general-purpose programming language (for UI, logic, communication).
Traditional Interfacing: Embedding SQL within the host programming language.
Persistent Programming Language: A programming language extended with constructs to handle persistent data seamlessly.
Distinction from Embedded SQL:
Type System: Embedded SQL has different type systems for host language and SQL (impedance mismatch). Programmer handles conversions. Persistent PL integrates the query language and host language, sharing the same type system. Objects stored without explicit type/format changes (transparency).
Data Handling: Embedded SQL requires explicit code to fetch data into memory and store updates back to disk. Persistent PL allows manipulation of persistent data without explicit fetch/store code (transparency).
Drawbacks of Embedded SQL Approach:
Type conversion code is error-prone (outside OO type system).
Significant code overhead for format translation and data loading/unloading.
Drawbacks of Persistent Programming Languages:
Safety: Powerful languages make it easier to introduce programming errors that damage the database.
Optimization: Complexity makes automatic high-level optimization (e.g., reducing disk I/O) harder.
Declarative Querying: Support for powerful, declarative querying is often lacking or less mature compared to SQL.
Focus: Extending Object-Oriented (OO) languages like C++ and Java to support persistence.
22.8.1 Persistence of Objects
Standard OO Objects: Are transient (vanish when program terminates).
Goal: Provide ways to make objects persistent.
Approaches:
Persistence by Class: Declare a class as persistent; all its objects become persistent by default. (Inflexible, often means “persistable” - objects can be made persistent).
Persistence by Creation: Use special syntax (e.g., extending new) to create persistent objects explicitly. Object is either persistent or transient from creation.
Persistence by Marking: Create all objects as transient. Explicitly mark an object as persistent before program termination if it needs to persist. Postpones the decision.
Persistence by Reachability: Declare one or more objects as root persistent objects. Any object reachable from a root object through a chain of references is also persistent. (Easy to make whole structures persistent, but burden on DB system to track reachability, can be expensive).
22.8.2 Object Identity and Pointers
Transient Object Identifier: Returned when creating a transient object. Valid only during the creating program’s execution. Often an in-memory pointer (e.g., in C++).
Persistent Object Identifier (OID): Assigned when a persistent object is created. Must remain valid across program executions and potentially database reorganizations.
Degrees of Permanence of Identity:
Intraprocedure: Valid only within a single procedure execution (e.g., local variables).
Intraprogram: Valid only during a single program/query execution (e.g., global variables, in-memory pointers).
Interprogram: Persists between program executions but may change if data storage changes (e.g., disk file pointers).
Persistent: Persists across executions AND structural data reorganizations. Required for OODBs.
Persistent Pointers: Implementation of persistent OIDs in persistent language extensions (e.g., Persistent C++). Act like pointers but remain valid across executions/reorganizations. Conceptually, a pointer to an object in the database.
22.8.3 Storage and Access of Persistent Objects
Storage:
Data: Instance variables stored individually for each object.
Code (Methods): Logically part of the database schema along with type definitions. Implementation varies: might be stored in DB or in external files.
Finding Objects in the Database:
Names: Assign names to objects (like file names). Suitable for small numbers of objects (e.g., entry points, collections).
Object Identifiers / Persistent Pointers: Expose OIDs, which can be stored externally. Can be physical pointers.
Collections: Store collections (sets, multisets, lists) of objects. Iterate over collections to find objects. Collections are often objects themselves.
Class Extents: A special collection containing all objects of a given class. Maintained automatically (object added on creation, removed on deletion). Allows treating classes like relations (can examine all instances).
Common Support: Most OODBs support all three access methods. Often name only entry points like class extents or key collection objects. Class extents often contain only the persistent objects of the class.
22.9 Object-Relational Mapping (ORM)
Definition: A third approach to integrating OO models/languages with databases. ORM systems provide a layer on top of a traditional relational database.
Core Idea: Allow programmers to work with objects in their programming language, while data is persisted in relational tables. Defines a mapping between database tuples and programming language objects.
Key Characteristics:
Objects are Transient: Objects manipulated by the program are typically in-memory and transient.
No Permanent Object Identity (in ORM): ORM itself doesn’t manage persistent OIDs in the same way OODBs do. Identity is often tied to relational primary keys.
Operations:
Retrieval: Retrieve data from the database based on selection conditions, create transient programming language objects based on the mapping.
Save/Update: Program modifies transient objects, creates new ones, marks objects for deletion. Issues a “save” command. ORM translates these changes into SQL INSERT, UPDATE, DELETE statements based on the mapping.
Example System:Hibernate (popular Java ORM). Described more in Section 9.4.2.
Primary Goal: Ease the job of application developers by providing an object model, while leveraging the robustness and features of relational databases.
Benefits:
Programmer works with objects.
Uses mature RDBMS technology.
Can provide performance gains via caching (operating on objects in memory).
Querying: ORMs provide object-oriented query languages (e.g., HQL, JPQL). These queries are translated into SQL to run on the underlying database. Results are converted back into objects.
Drawbacks:
Overhead: Can introduce significant overhead, especially for bulk database updates.
Limited Querying: Object query languages might not support all the complex queries possible in SQL.
Workarounds: It’s usually possible to bypass the ORM for specific tasks and issue native SQL directly for complex queries or bulk updates.
Adoption: ORM systems have seen widespread adoption in recent years, far exceeding that of persistent programming languages/OODBs.
22.10 Object-Oriented versus Object-Relational
Summary of Approaches Studied:
Object-Relational Databases (ORDBMS): Object features (complex types, inheritance, references) built on top of the relational model (SQL extensions).
Object-Oriented Databases (OODBMS): Built around persistent programming languages, native object models.
Object-Relational Mapping (ORM): Object layer implemented over a traditional relational database.
Comparison and Target Markets:
Relational Systems (RDBMS):
Strengths: Simple data types, powerful declarative query language (SQL), high protection/integrity, well-understood optimization.
Weaknesses: Historically poor support for complex data types.
Persistent Programming Language OODBs:
Strengths: Complex data types, tight integration with programming language (reduced impedance mismatch), potentially high performance (low-overhead access, caching).
Weaknesses: More susceptible to data corruption via programming errors, weaker/less standardized declarative query capabilities, optimization challenges.
Typical Applications: CAD, specialized domains needing high performance.
Object-Relational Systems (ORDBMS):
Strengths: Complex data types, powerful query language (extended SQL), high protection (leveraging relational foundations).
Weaknesses: Can be complex; performance characteristics vary.
Typical Applications: Storage/querying complex/multimedia data within a robust framework.
Object-Relational Mapping Systems (ORM):
Strengths: Complex data types integrated with programming languages (object model for developers), built on standard RDBMS (robustness, mature tooling).
Blurring Boundaries: Some systems combine aspects. OODBs can be implemented on top of RDBMS/ORDBMS (trading some performance for robustness).
22.11 Summary
The object-relational data model extends the relational model with a richer type system (collections, structured types) and object orientation (inheritance, references).
Collection types include nested relations, sets, multisets, and arrays.
Object orientation adds type/table inheritance (subtypes/subtables) and object/tuple references.
SQL standards (SQL:1999, SQL:2003) include extensions for these features, aiming to preserve relational foundations (declarative access) while adding modeling power.
Object-relational database systems offer a migration path for relational users needing OO features.
Persistent extensions to C++ (ODMG standard) and Java (JDO standard) aim for seamless integration of persistence with language constructs.
Object-relational mapping (ORM) systems provide an object view over relational data, creating transient objects on demand. ORMs are widely adopted, unlike the more limited adoption of persistent PLs.
Different approaches (Relational, OODB/Persistent PL, O-R DB, ORM) have different strengths, weaknesses, and target applications, particularly regarding type complexity, query power, performance, and protection.
Review Terms
Nested relations
Nested relational model
Complex types
Collection types
Large object types (LOBs - mentioned briefly in implementation, not detailed conceptually in this chapter text)