1. Introduction: Computer Vision and Machine Learning
1.1 What is Computer Vision?
- Computer Vision (CV) is a field that enables computers to “see” and interpret the visual world (images and videos).
- Fundamentally, Computer Vision is a Machine Learning problem.
1.2 Relationship to Machine Learning Types
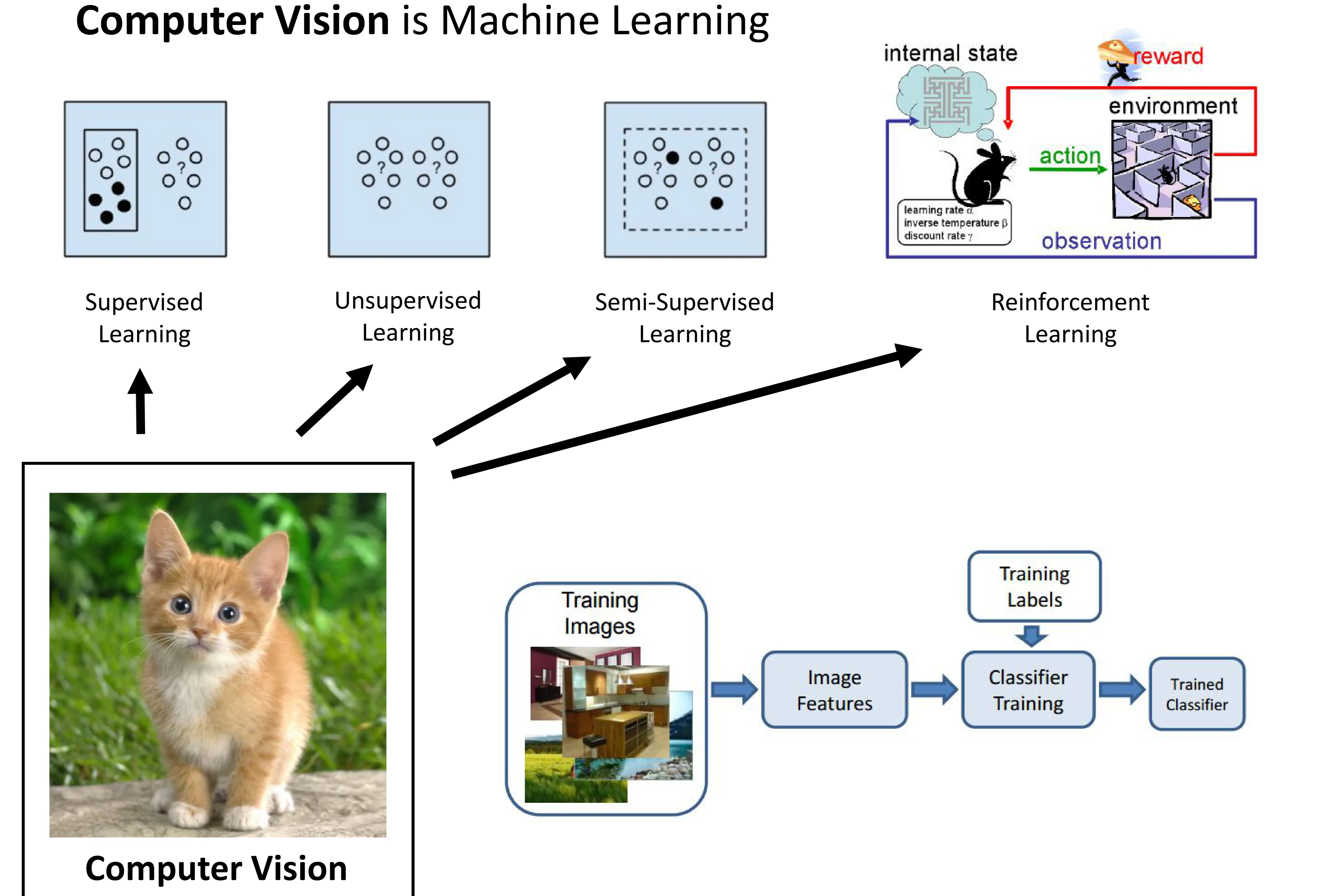
- Computer Vision tasks often utilize various Machine Learning paradigms:
- Supervised Learning: Learning from labeled data. (e.g., image classification where images are labeled with object names). This is the most common approach for tasks shown in the pipeline.
- Pipeline: Training Images → Extract Image Features → Classifier Training (using Training Labels) → Trained Classifier.
- Unsupervised Learning: Learning patterns from unlabeled data. (e.g., clustering similar images together without predefined categories).
- Semi-Supervised Learning: Learning from a mix of labeled and unlabeled data.
- Reinforcement Learning: Learning through trial and error via rewards and penalties based on actions taken in an environment. (e.g., training an agent to navigate based on visual input).
- Supervised Learning: Learning from labeled data. (e.g., image classification where images are labeled with object names). This is the most common approach for tasks shown in the pipeline.
1.4 Core ML Tasks in CV
- Regression: The output variable takes continuous values. (e.g., predicting the angle of steering wheel from an image).
- Classification: The output variable takes discrete class labels. (e.g., identifying the object in an image as “cat”, “dog”, or “hat”).
- Note: Underneath, classification models often produce continuous values (like probabilities) representing the likelihood of belonging to each class.
2. The Challenge of Computer Vision
2.3 Why Computer Vision is Hard: Sources of Variation
(Diagram Description: Multiple grids of images illustrating various challenges.)
- CV is difficult for computers due to numerous variations present in real-world images:
- Viewpoint variation: Objects look different from different angles.

- Scale variation: Objects appear at different sizes.
- Deformation: Objects can be non-rigid and change shape.
- Occlusion: Objects can be partially hidden.
- Illumination conditions: Lighting affects object appearance drastically.
- Background clutter: Objects can blend into a complex background.
- Intra-class variation: Objects within the same category can look very different.


3. Image Classification: Pipeline and Datasets
3.1 Image Classification Pipeline (Revisited)
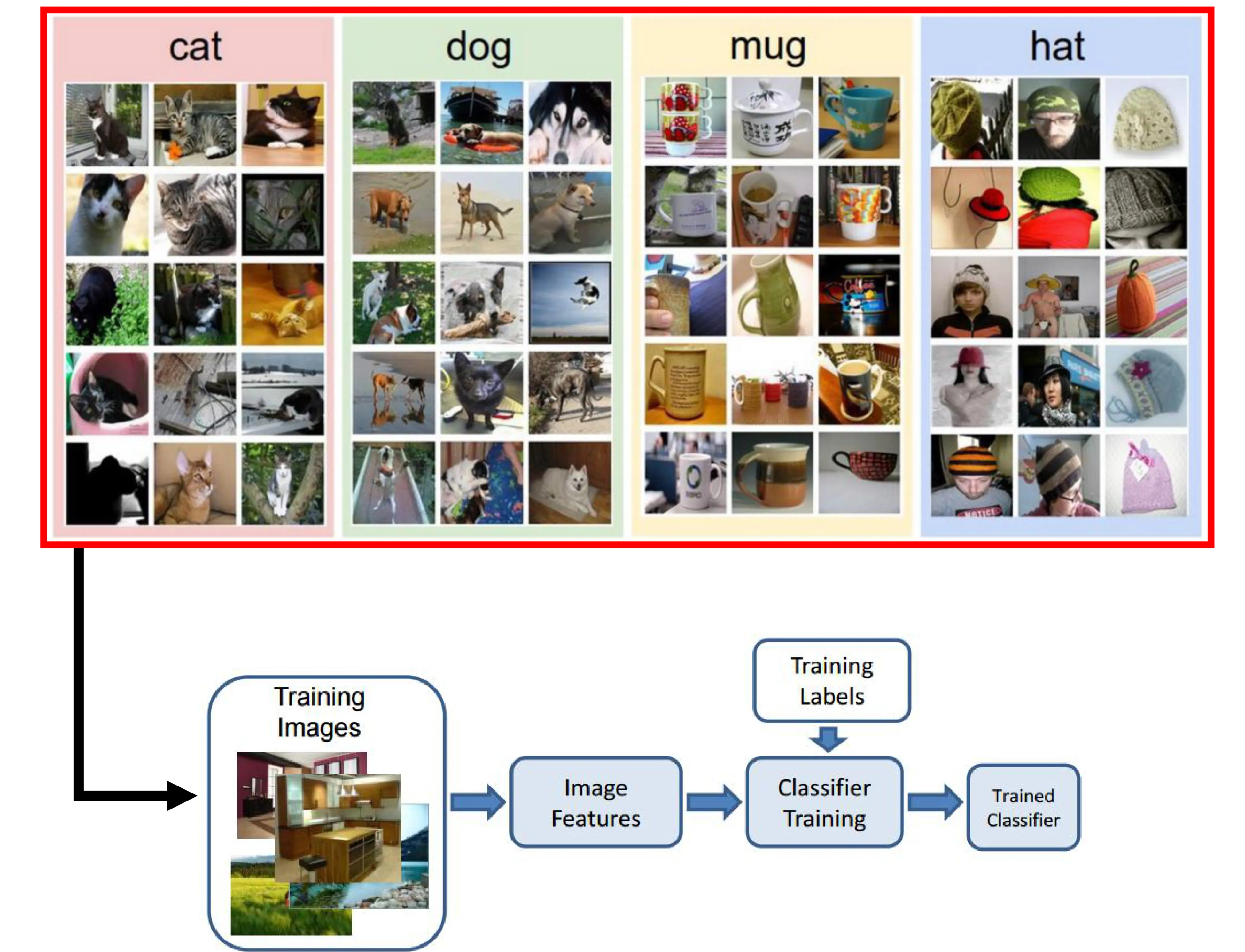
- Goal: Assign a label (e.g., “cat”, “dog”) to an input image.
- Standard Pipeline:
- Input: Training Images (labeled examples).
- Feature Extraction: Extract meaningful features (historically hand-crafted, now learned by Deep Learning).
- Classifier Training: Train a model using features and labels.
- Output: Trained Classifier capable of predicting labels for new images.
3.2 Famous Computer Vision Datasets
- MNIST: Handwritten digits ( ). Grayscale images. Often used as a basic benchmark.
- ImageNet: Large-scale dataset based on WordNet hierarchy. Over million images, categories. Used in the ILSVRC challenge.
- Dataset Details: Contains links to images, not the images themselves.
- Example Hierarchy: High-level category “fruit” has images. Sub-category “Granny Smith apples” has images.
- CIFAR-10 / CIFAR-100: Datasets of small ( ) color images. CIFAR-10 has 10 classes, CIFAR-100 has 100 classes.
- Places: Large-scale dataset focused on scene recognition (e.g., “kitchen”, “beach”, “street”).

4. Simple Classifier: Image Difference & K-Nearest Neighbors
4.1 Building a Classifier for CIFAR-10
- Task: Classify color images into 10 categories. (Image: CIFAR-10 examples)
4.2 Image Difference Classifier (Nearest Neighbor with L1/L2)
-
Concept: Compare a test image to every training image and find the closest match based on pixel differences. Assign the label of the closest training image.
-
Pixel-wise Distance:
- L1 Distance (Manhattan Distance): Sum of absolute differences between corresponding pixels.
- (where indexes pixels)
- (Example Calculation:
- Test Image Patch (Top-Left ):
- Training Image Patch (Top-Left ):
- Pixel-wise Absolute Differences:
- Summing all differences across the entire image gives the L1 distance. The example shows a simplified sum of for patches shown.*
- L2 Distance (Euclidean Distance): Square root of the sum of squared differences between corresponding pixels.
- L1 Distance (Manhattan Distance): Sum of absolute differences between corresponding pixels.
-
CIFAR-10 Accuracy:
- Random Guessing:
- Image-Diff (L1):
- Image-Diff (L2):
4.3 K-Nearest Neighbors (KNN)
-
Concept: Generalization of the simple image difference classifier. Instead of just finding the single nearest neighbor, find the nearest neighbors and have them vote for the class label.

-
Hyperparameters: Values set before training, like in KNN or the distance metric (L1/L2).
-
Tuning Hyperparameters: Finding the best hyperparameter values.
- Problem: Cannot use the test set for tuning (prevents evaluating true generalization).
- Solution: Cross-Validation:
- Split training data into folds (e.g., 5 folds).
- Train on folds, validate on fold. Repeat times, holding out a different fold each time.
- Average the validation performance across folds for a given hyperparameter value.
- Choose the hyperparameter value that performed best on average during cross-validation.
- Finally, train the model on the entire training set using the best hyperparameter. Evaluate on the test set once.
- (Diagram: Training data split into ‘fold 1’…‘fold 5’ and ‘test data’)
- (Diagram: Plot of Cross-validation accuracy vs. k for KNN on CIFAR-10. Shows peak accuracy around k=7)
-
CIFAR-10 Accuracy with KNN:
- Training and testing on the same data (using L2): (Overfits)
- 7-Nearest Neighbors (tuned via cross-validation): ~
- Human Performance: ~
- Convolutional Neural Networks (CNNs): ~ (Spoiler: Much better!)
5. Neural Networks Fundamentals (Reminders)
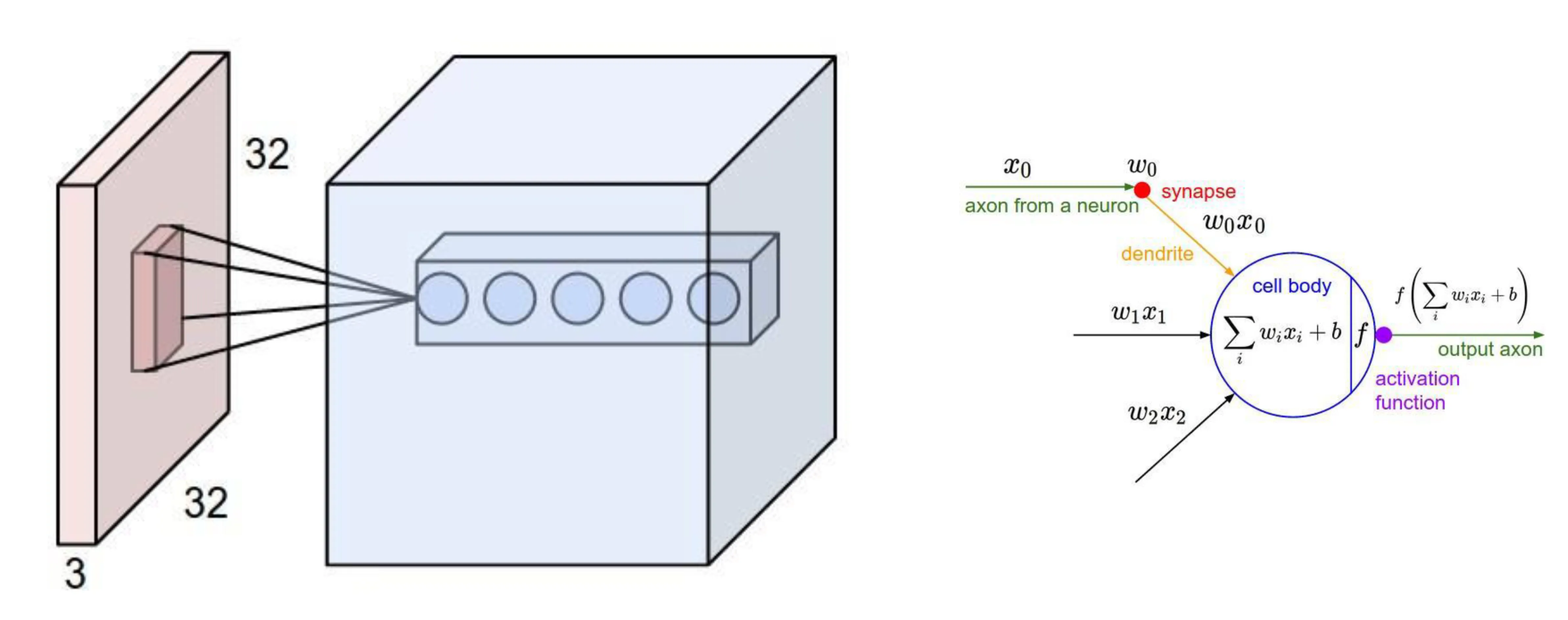
5.1 Reminder: Weighing the Evidence (Perceptron/Neuron)
- Neuron Model: Takes multiple inputs, computes a weighted sum, adds a bias, and applies an activation function.
- Process:
- Weigh: Multiply each input () by its weight ().
- Sum up: Calculate the weighted sum and add bias .
- Activate: Apply a non-linear activation function (e.g., sigmoid, step function) to produce the output. .
- Simple Threshold Activation: (Note: Bias can be incorporated into the threshold.)
5.2 Reminder: “Learning” is Optimization of a Function
(Diagram Description: Block diagram showing forward/backward pass. Input image → differentiable block (NN) → log probabilities. Correct label influences gradients, used in backward pass to update weights. Also shows a 3D plot of a loss function surface with a minimum.)
- Learning: Adjusting the model’s parameters (weights and biases ) to minimize a loss function, which measures how poorly the model performs on the training data.
- Supervised Learning Process:
- Forward Pass: Input data goes through the network to produce an output (e.g., class probabilities or scores ).
- Loss Calculation: Compare the output to the ground truth label using a loss function .
- Backward Pass (Backpropagation): Calculate the gradients of the loss function with respect to the parameters ( ). Gradients indicate the direction to adjust parameters to decrease the loss.
- Parameter Update: Update weights and biases using an optimization algorithm (like Gradient Descent) based on the calculated gradients.
- Loss Function Example (Mean Squared Error - often used in regression, related to classification losses):
- Where is the number of training examples, is the ground truth label vector for input , and is the network’s output vector.
- Ground Truth Example (for digit “6” in MNIST):
- (One-hot encoded vector)
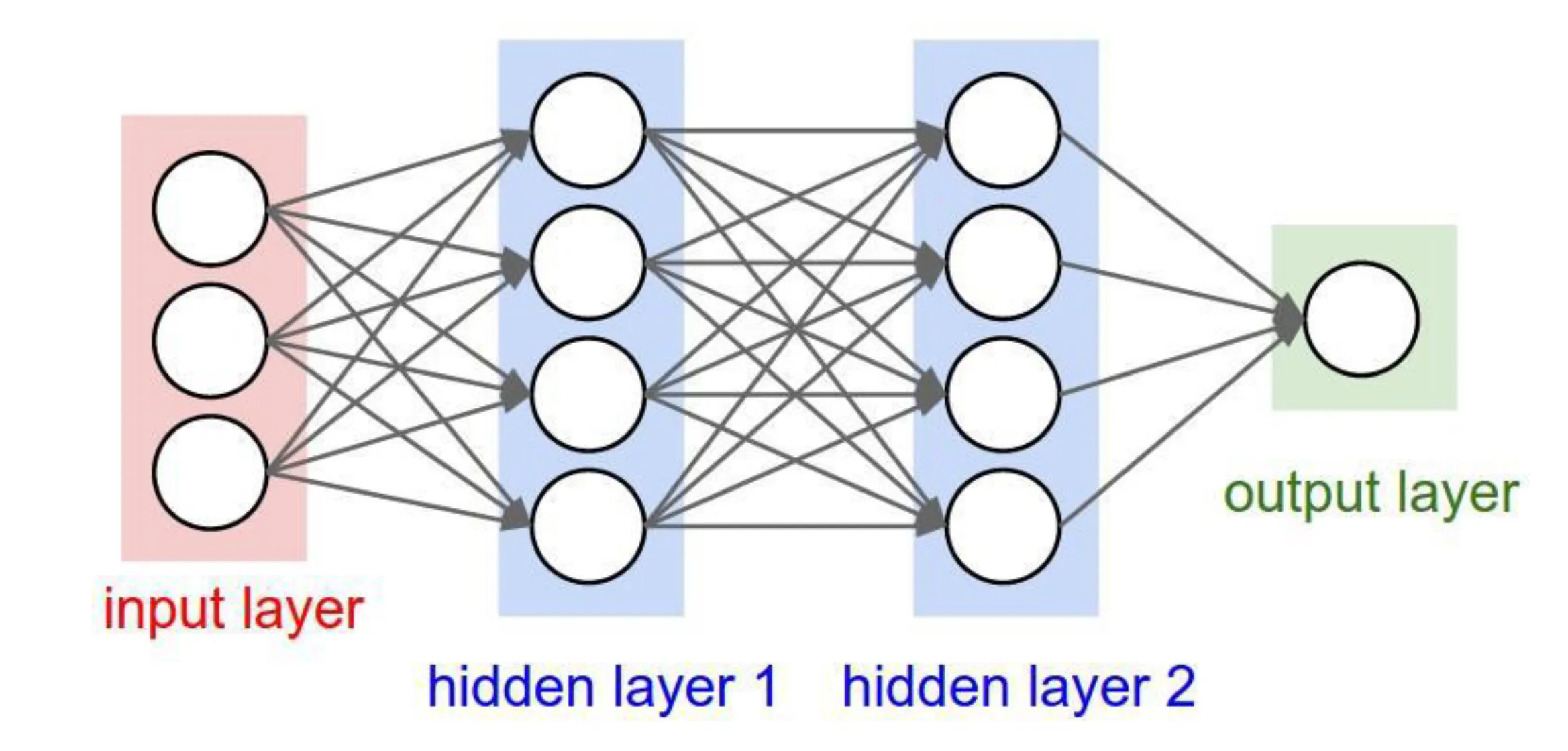
5.3 Example: Neural Network for MNIST
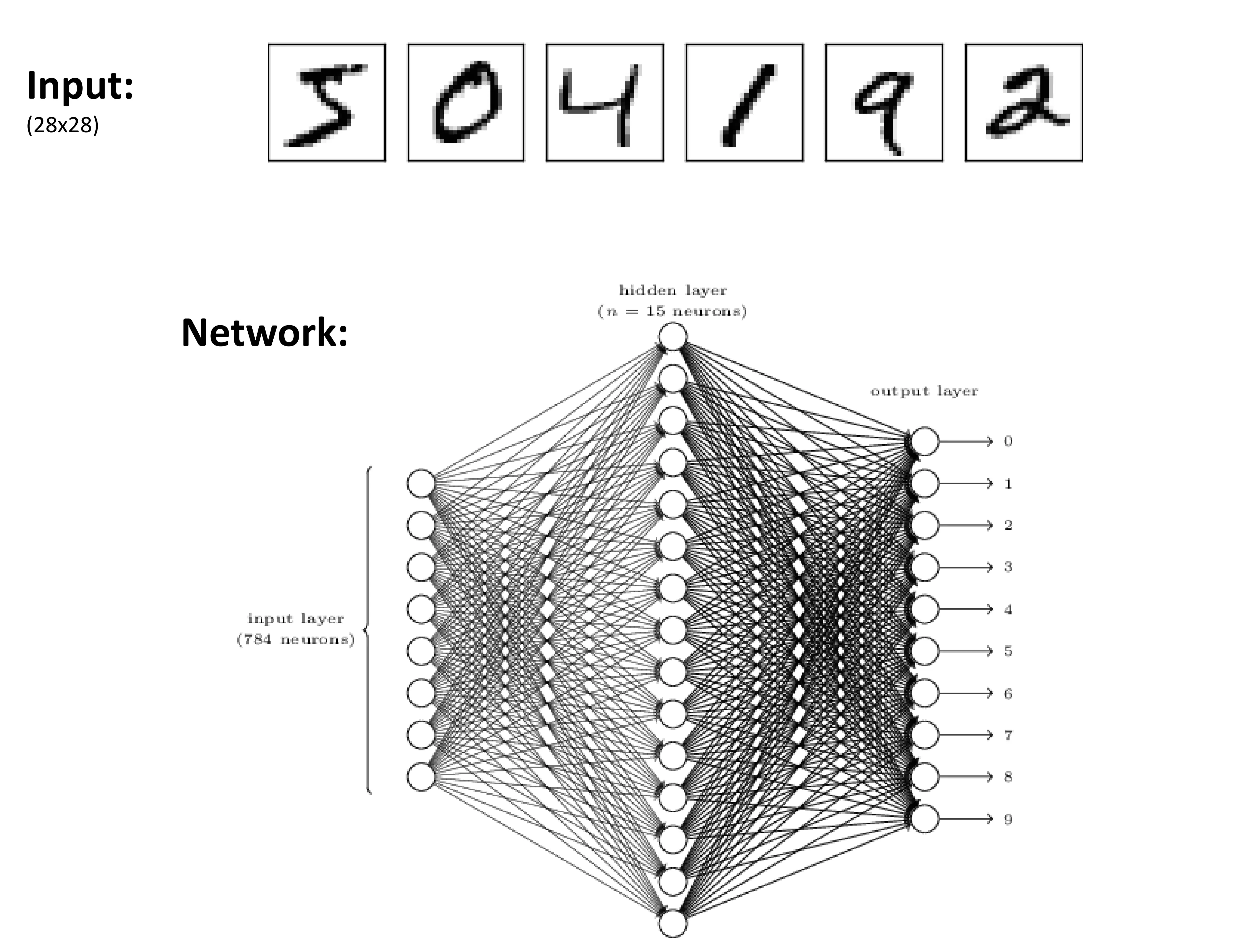
- Input: Flattened MNIST image ( pixels).
- Network:
- Input Layer: neurons.
- Hidden Layer: Fully connected layer with neurons (example).
- Output Layer: Fully connected layer with neurons, each corresponding to a digit class ( through ). Outputs often represent class scores or probabilities (after softmax).
6. Convolutional Neural Networks (CNNs)
6.1 Introduction to CNNs
-
Regular Neural Network (Fully Connected): Neurons in one layer are connected to all neurons in the next layer. Treats input (like an image) as a flat vector. Does not account for spatial structure.
-
Convolutional Neural Network: Designed specifically for processing grid-like data, such as images. Takes advantage of spatial structure.
-
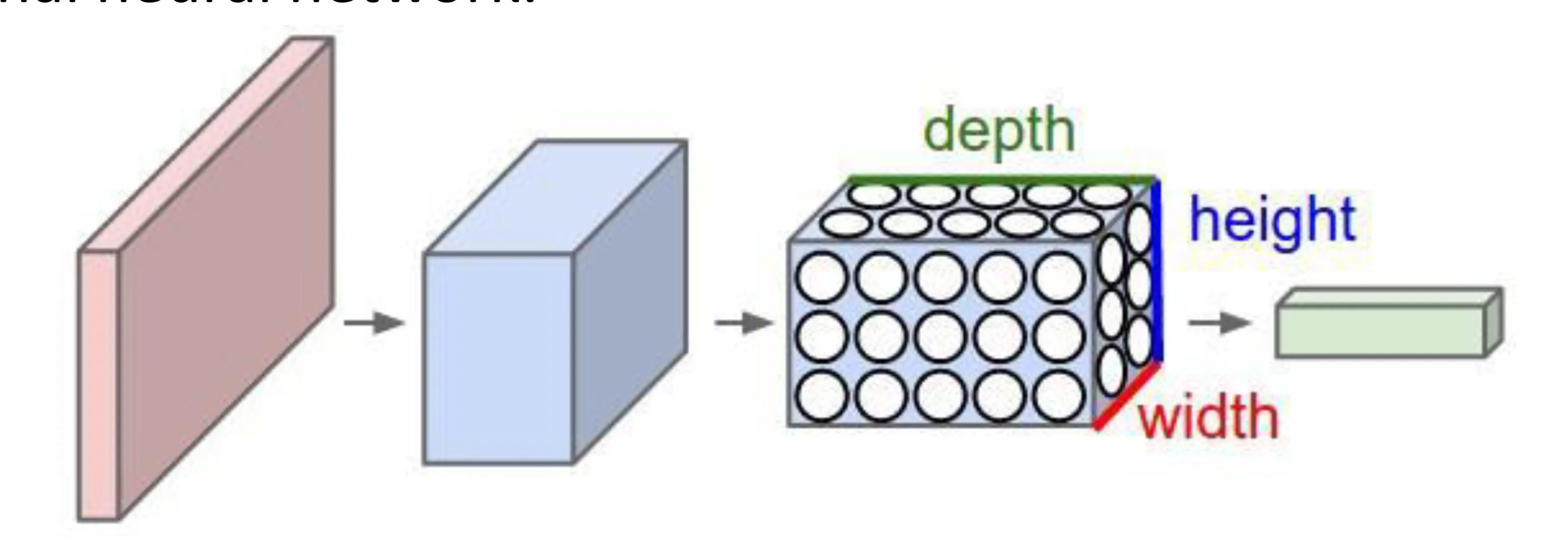
-
Layers process data in 3D volumes: depth, height, width.
-
Each layer transforms an input 3D volume to an output 3D volume using a differentiable function (which may or may not have learnable parameters).
-
6.2 CNN Layers

- Common Layers:
- INPUT e.g., : Holds raw pixel values of the input image. Dimensions are (height width depth/channels). Depth is for R, G, B color channels.
- CONV (Convolutional Layer): Computes output of neurons connected to local regions in the input volume (receptive field). Performs convolutions (dot products between filter weights and input regions). Preserves spatial structure.
- Learnable parameters: Filters (weights) and biases.
- Example output volume: if using filters.
- RELU (Rectified Linear Unit): Element-wise activation function. Applies . Introduces non-linearity without changing volume size.
- No learnable parameters.
- Example output volume: (same as input).
- POOL (Pooling Layer): Downsamples the volume along spatial dimensions (width, height). Reduces computation, increases robustness to small spatial variations. Common types: Max Pooling, Average Pooling.
- No learnable parameters.
- Example output volume: (downsampled width/height).
- FC (Fully-Connected Layer): Standard neural network layer where each neuron is connected to all numbers in the previous volume. Usually found near the end of the network for classification.
- Learnable parameters: Weights and biases.
- Example output volume: for 10 class scores (e.g., in CIFAR-10). Each of the numbers corresponds to a class score.
6.3 CONV Layer: Local Connectivity
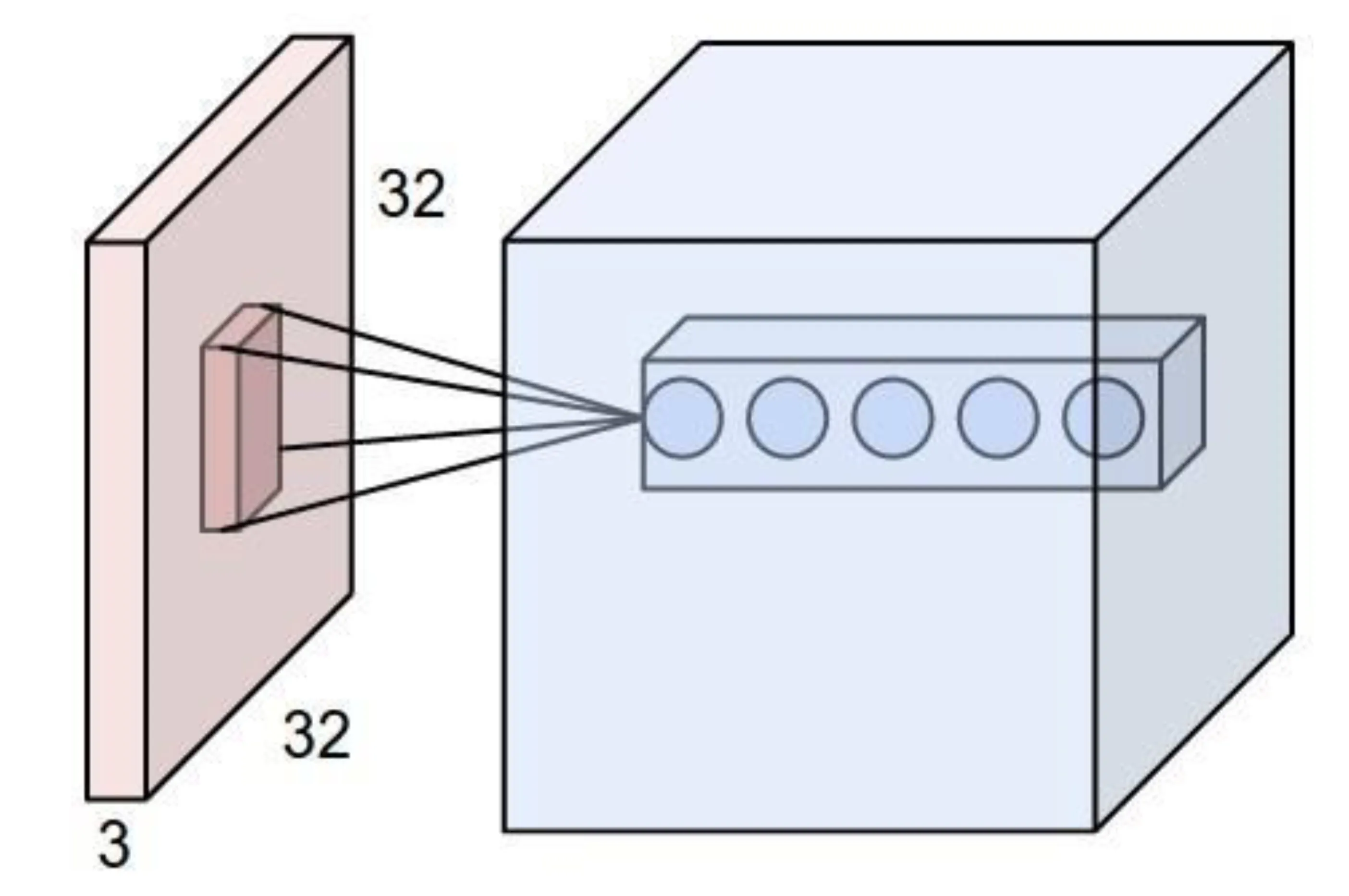
- Neurons in a CONV layer are only connected to a small, local region of the input volume (their receptive field).
- The extent of this connectivity is determined by the filter size.
- This contrasts with FC layers where neurons connect to the entire input.
6.4 CONV Layer: Shared Parameters (Weight Sharing)
- The same set of weights (the filter or kernel) is used for all neurons within the same depth slice of the output volume.
- Neurons at different spatial locations ( ) in the same output slice use the identical filter, just applied to different input patches.
- Rationale: If a feature detector (like a horizontal edge detector) is useful in one part of the image, it’s likely useful in other parts too.
- Dramatically reduces the number of parameters compared to FC layers.
6.5 CONV Layer: Spatial Arrangement of Output Volume
-
The output volume’s dimensions are controlled by three hyperparameters:
- Depth: Number of filters used. Each filter learns to detect a different feature. The output volume will have a depth equal to the number of filters.
- Stride ( ): Step size the filter takes as it slides across the input volume. Larger stride produces smaller output spatial dimensions.
- Padding ( ): Amount of zero-padding added around the border of the input volume. Often used to control the output spatial dimensions (e.g., preserve input width/height).
-
Output Size Calculation (Width or Height):
- Given input size , filter size , stride , padding .
- Output size
- (Must result in an integer).
6.7 Example Convolution Filters
- Identity: Outputs the original image (approximately).
- Edge Detection: Detects edges/gradients.
6.8 Convolution as Representation Learning
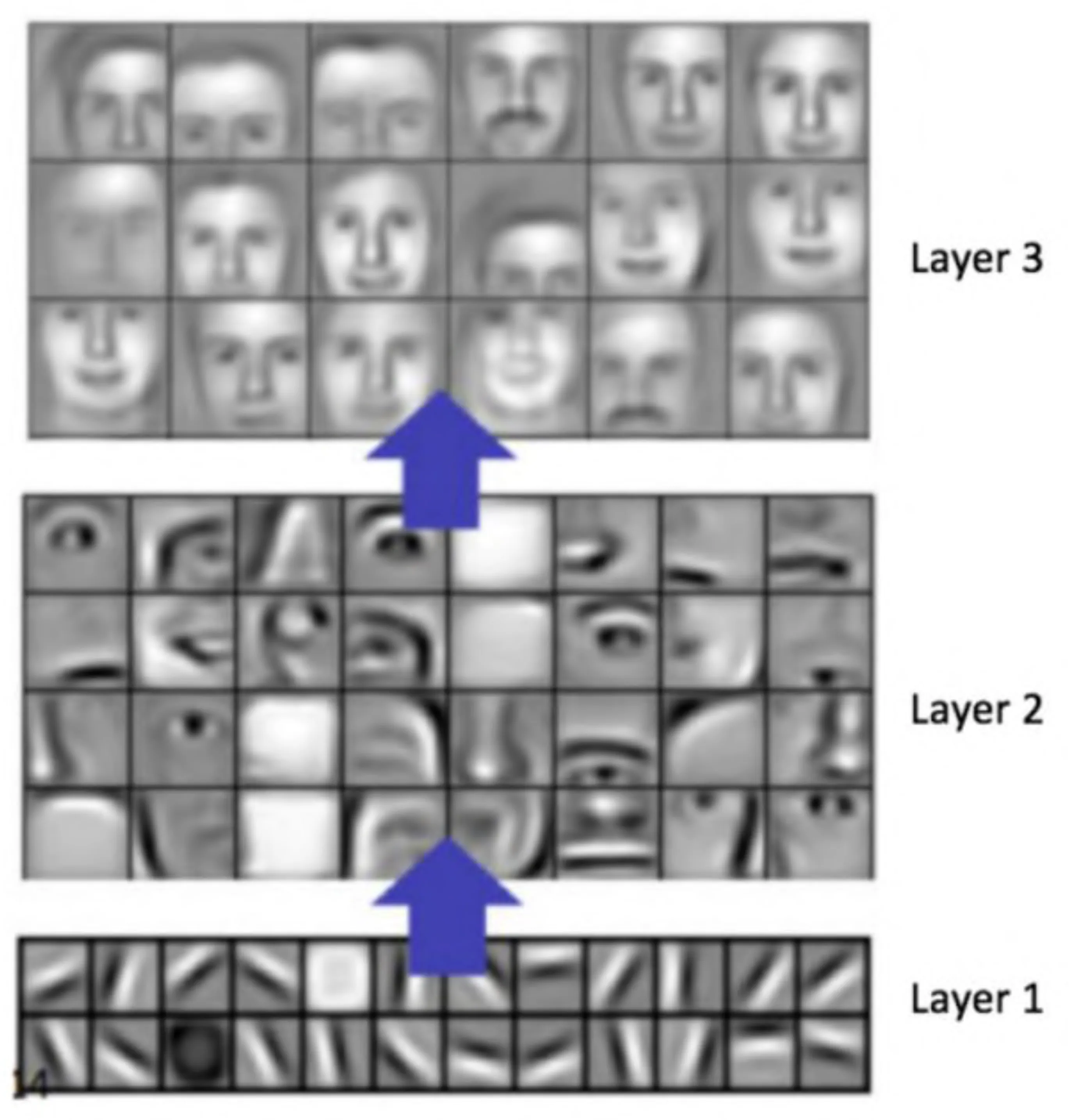
- CNNs learn hierarchical representations automatically.
- Layer 1: Learns basic features like edges, corners, color blobs. (Image: Grid of Gabor-like filters)
- Layer 2: Combines Layer 1 features to learn more complex patterns like textures, parts of objects (e.g., eyes, noses).
- Layer 3 (and deeper): Combines Layer 2 features to learn representations of object classes.
6.9 POOL Layer: Pooling
- Purpose: Reduce spatial dimensions (width, height) of the volume. Makes representation more robust to small translations and distortions. Reduces computational cost.
- Max Pooling: Slides a window over the input volume slice and takes the maximum value within that window.
- Example: Max pool with filters and stride .
- Input Slice:
- Output Slice:
- Reduces width and height, keeps depth the same.
- Example Volume Downsampling: .
7. CNN Architectures and Applications
7.1 Generic CNN Architecture for Classification
(Diagram: Input → [CONV → RELU → POOL] repeating → FC → Output)*
- A common pattern involves stacking CONV, RELU, and POOL layers, followed by one or more FC layers for final classification.
7.2 Adaptable Architecture for Many Applications
- The core CNN architecture (convolutional base) acts as a powerful feature extractor.
- The final layers can be modified for different tasks beyond simple classification:
- Different Image Classification Domains: Use the same architecture, retrain/fine-tune on new domain data.
- Image Captioning: Add Recurrent Neural Networks (RNNs) like LSTMs to generate sequences (text descriptions).
- Image Object Localization: Output bounding box coordinates ( ) in addition to class labels.
- Image Segmentation: Use Fully Convolutional Networks (FCNs) or Deconvolution Layers to output a prediction for every pixel (semantic segmentation).
7.3 Case Study: ImageNet (ILSVRC)
- ImageNet Large Scale Visual Recognition Challenge (ILSVRC): Annual competition driving progress in CV, particularly object classification and detection.
- Dataset: Subset of ImageNet, typically million training images, validation images, test images, for object categories.
- Evaluation Metric (Classification): Top-5 Error Rate
- The model predicts probabilities for all classes.
- It gets credit if the correct label is among its top predictions.
- Top-5 error is the percentage of test images where the correct label is not in the top 5.
- (Diagram: Example showing ground truth “Steel drum”, one prediction getting Accuracy: 1 (correct label in top 5), another getting Accuracy: 0)
- Top-5 error is significantly lower than Top-1 error (e.g., ~20% reduction mentioned for AlexNet 2012).
- Human Performance: Humans annotated the test set using a binary task (“apple” or “not apple”), achieving very low error rates (often cited around , later models surpassed this).
7.4 Evolution of CNN Architectures on ImageNet
(Diagram: Bar chart showing decreasing Top-5 error rate from 2012 to 2015/2016)
- AlexNet (2012): First major CNN success on ILSVRC.
- Top-5 Error: (originally 16.4% shown in chart)
- Architecture: layers (5 CONV, 3 FC). Used RELU, Dropout, Data Augmentation.
- Parameters: million.
- (Diagram: AlexNet layer structure C1, P1, N1… FC8)
- ZFNet (2013): Improvement on AlexNet by tuning hyperparameters, especially filter size and stride in early layers. Visualized features.
- Top-5 Error: (originally 11.7% shown)
- Architecture: layers. More filters, denser stride.
- VGGNet (2014): Showed depth is critical. Very uniform architecture.
- Top-5 Error:
- Architecture: or layers. Used only small CONV filters (stacked) and POOL layers.
- Parameters: million (very large).
- (Diagram: VGGNet vs AlexNet structure, VGG’s uniform blocks)
- GoogLeNet (2014): Focused on computational efficiency while increasing depth. Introduced Inception Module.
- Top-5 Error:
- Architecture: layers. Used Inception modules which perform convolutions with multiple filter sizes ( ) in parallel and concatenate results. Used global average pooling instead of final FC layers.
- Parameters: million (much smaller than AlexNet/VGG).
- (Diagram: Overall GoogLeNet structure with stacked Inception modules. Detail of one Inception module.)
- ResNet (Residual Network) (2015): Enabled training of much deeper networks using Residual Connections (Skip Connections). Addressed vanishing gradient problem in very deep networks.
- Top-5 Error: (First to surpass reported human-level performance on this specific task)
- Architecture: Up to layers. Residual blocks learn , where input is added back via a skip connection: . Easier to learn identity mapping.
- Parameters: Varies with depth. More layers generally led to better performance.
- (Diagram: Plain vs Residual network comparison. Detail of a residual block with skip connection.)
- CUImage (2016): Further improvements, often using ensembles (combining multiple models).
- Top-5 Error:
- Method: Ensemble of models (likely ResNet variants or similar).
7.5 Other Advanced Applications
-
Segmentation:
- Semantic Segmentation: Classify every pixel in an image.
- Fully Convolutional Networks (FCNs): Replace FC layers in classification networks with CONV layers to produce heatmaps. Upsample heatmap to get pixel-wise predictions.

-
Object Detection: Identify object classes and locate them with bounding boxes.
- R-CNN (Regions with CNN features):
- Propose candidate regions (~ ) using selective search.
- Warp each region to fixed size.
- Extract CNN features (e.g., from AlexNet) for each warped region.
- Classify regions using SVMs.
- Refine bounding boxes using regression.
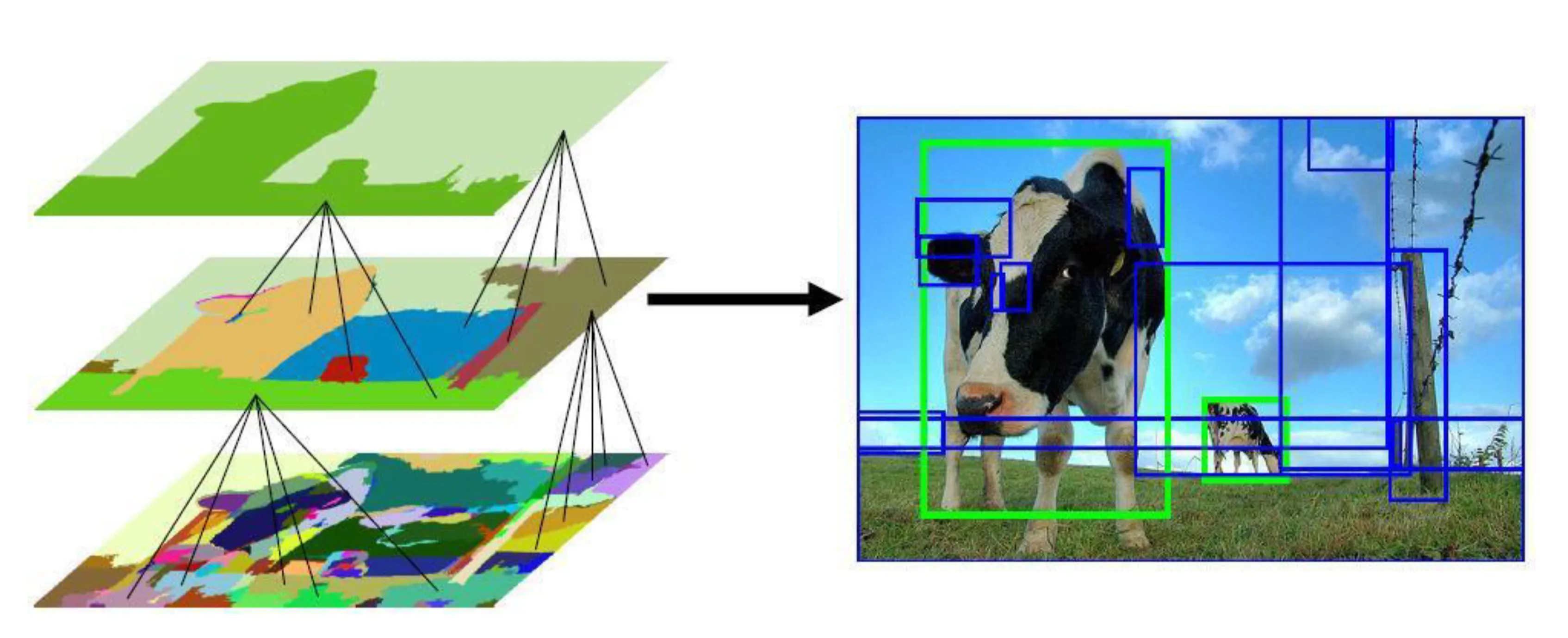
- R-CNN (Regions with CNN features):
-
Image Caption Generation: Generate a natural language description of an image.
- Often uses a CNN (feature extractor) combined with an RNN/LSTM (sequence generator). Attention mechanisms often used.
- (Diagram: Example image “man sitting on a couch with a dog” with generated captions. Attention visualization highlighting image regions corresponding to words “dog”, “man”, “sitting”, “couch”. Pipeline: detect words → generate sentences → re-rank sentences)
-
Image Question Answering (VQA): Answer natural language questions about an image.
- Combines CNN (for image features) and RNN/LSTM (for question encoding) to predict an answer.
- (Diagram: Example questions/answers for different images. VQA model architecture: Image→CNN, Question→WordEmbedding→LSTM, combined features → Softmax → Answer)
- Code:
https://github.com/renmengye/imageqa-public
-
Video Description Generation: Generate captions for video clips.
- Uses CNNs for frame-level features combined with RNNs/LSTMs across time to generate descriptions.
- (Diagram: S2VT (Sequence-to-Sequence Video to Text) architecture. Examples of correct/incorrect descriptions for videos.)
- Code:
https://vsubhashini.github.io/s2vt.html
-
Modeling Attention Steering: Models that learn where to look in an image sequentially to perform a task (like object recognition).
- Recurrent Attention Model (RAM): Uses RNNs to decide the next “glimpse” location based on past glimpses.
- (Diagram: Examples of attention glimpses on digits. RAM architecture diagram.)
-
Audio Classification: Applying CNNs (often 1D CNNs or 2D CNNs on spectrograms) to audio tasks.
- (Diagram: Spectrograms comparing “Dry Road” vs. “Wet Road” tire noise)
-
Driving Scene Segmentation: Semantic segmentation applied to autonomous driving context.
- (Diagram: Driving scene image and its pixel-wise segmentation into classes like Sky, Building, Road, Pavement, Tree, Car, Pedestrian, etc.)
-
End-to-End Learning of Driving Task: Training a model (often CNN) to directly predict driving controls (e.g., steering angle) from raw sensor input (e.g., camera images).
- (Diagram: Comparison of human/Tesla control vs. learned control steering wheel visualizations. Plot of steering angle over time.)
- Project:
http://cars.mit.edu/deeptesla
7.6 Vision for Intelligent Systems Hierarchy
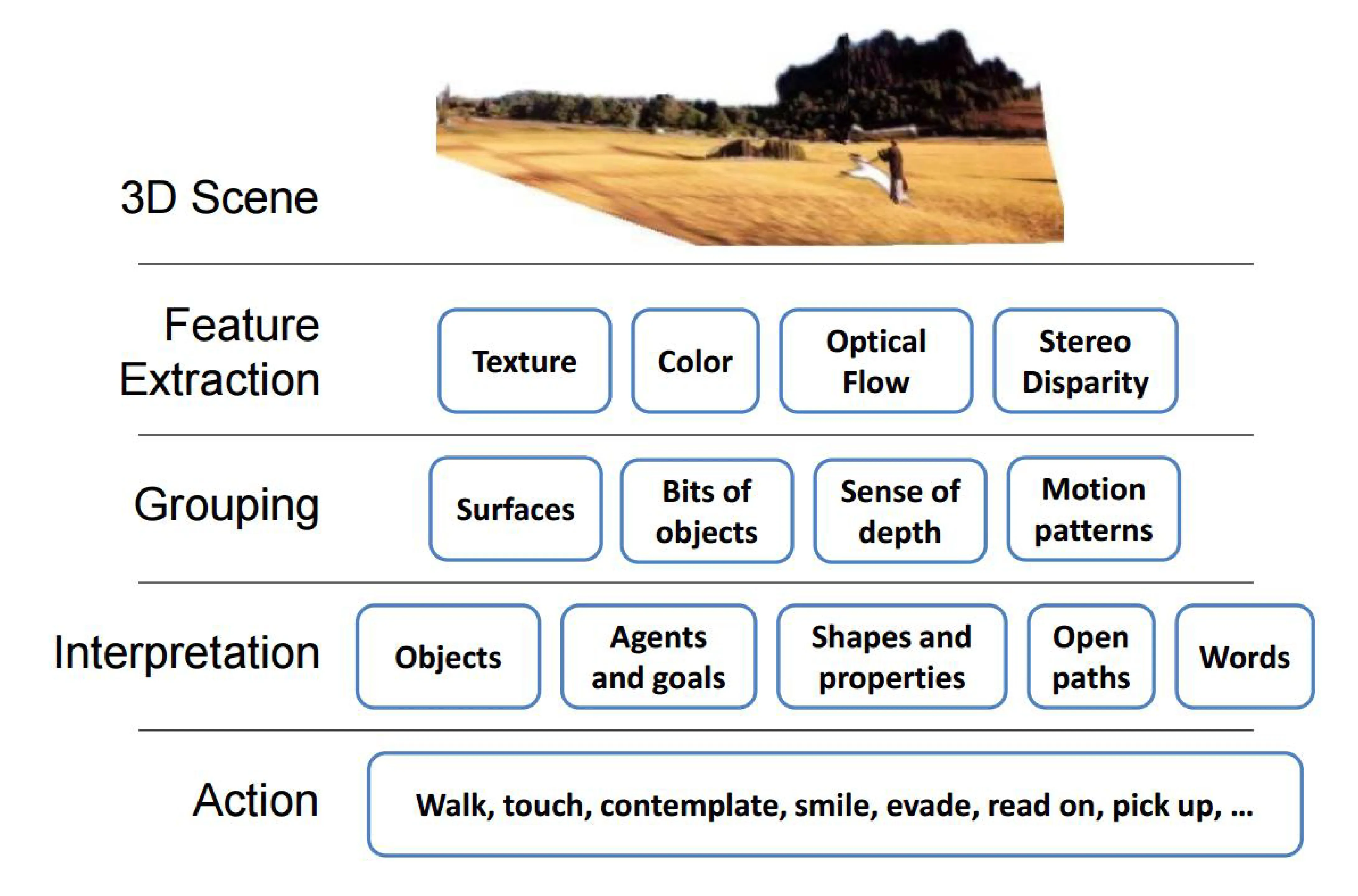
- 3D Scene: The physical world.
- Feature Extraction: Detect low-level features (Texture, Color, Optical Flow, Stereo Disparity).
- Grouping: Group features into surfaces, bits of objects, infer depth, motion patterns.
- Interpretation: Recognize objects, agents/goals, shapes/properties, open paths, understand semantics (Words).
- Action: Interact with the world (Walk, touch, contemplate, smile, evade, read on, pick up, …).
8. Open Problems and Challenges
8.1 Robustness: Adversarial Examples
- Deep neural networks can be surprisingly fragile and non-robust.
- Problem 1: High Confidence on Unrecognizable Images:
- Networks can be fooled into classifying meaningless noise patterns or generated patterns as real objects with extremely high confidence ( ).
- (Image: Noise patterns confidently classified as “robin”, “cheetah”, “armadillo”, “lesser panda”. Geometric/texture patterns classified as “king penguin”, “starfish”, “baseball”, “electric guitar”.)
- Reference: Nguyen et al. 2015
- Problem 2: Fooled by Small Distortions:
- Adding carefully crafted, often imperceptible, perturbations to a legitimate image can cause the network to misclassify it completely.
- (Image: Original image (e.g., school bus) classified correctly. Adding small distortion causes it to be misclassified as “ostrich”.)
- Reference: Szegedy et al. 2013
8.2 Object Category Recognition Challenges (Examples)
(Images: Series of cat photos illustrating challenges)
- Occlusion (Cat behind table leg, cat peeking from behind tree).
- Unusual poses/context (Cat paw reaching into food bowl).
- Challenging appearance (Cat wearing a lion mane, cat in a monkey suit). These highlight the need for robustness against variations not well-represented in standard training sets.