Binary Classification
Problem Definition
- Given: Training data consisting of pairs for .
- is the feature vector for the -th data point (input).
- is the class label for the -th data point (output).
- Goal: Learn a classifier function such that it can predict the class label for new, unseen data points.
- Desired Property: For the training data, the classifier should ideally satisfy:
- Correct Classification Condition: This can be concisely written as for a correct classification. (Note: The boundary case is sometimes included in the positive class, as shown in the slide definition).
Review of Linear Classifiers
Linear Separability
- Definition: A dataset is linearly separable if there exists a linear discriminant function (a line in 2D, a plane in 3D, a hyperplane in higher dimensions) that can perfectly separate the data points of the different classes.
Linear Classifiers: Definition and Form
- General Form: A linear classifier has the discriminant function:
- : Weight vector.
- : Bias (or intercept).
- : Input feature vector.
- Decision Boundary: The boundary between the classes is defined by the equation , which is:
- Geometric Interpretation:
- In 2D: The decision boundary is a line.
- is the vector normal (perpendicular) to the line.
- determines the offset of the line from the origin.
- Points on one side of the line have , points on the other side have .
- In 3D: The decision boundary is a plane. is the normal vector to the plane.
- In nD (n > 3): The decision boundary is a hyperplane. is the normal vector to the hyperplane.
- In 2D: The decision boundary is a line.
- Comparison with K-NN:
- K-NN: Requires storing (
carrying) the entire training dataset to make predictions. - Linear Classifier: Uses the training data only to learn the parameters and . After learning, the training data is discarded. Only and are needed for classifying new data.
- K-NN: Requires storing (
The Perceptron Classifier
- Goal: Given linearly separable data with labels , find a weight vector and bias such that the discriminant function correctly separates all data points, i.e., .
- Finding the Separating Hyperplane: The Perceptron Algorithm provides a method.
The Perceptron Algorithm
- Homogeneous Coordinates (Optional but convenient):
- Rewrite the classifier as , where are the weights for the original features and is the bias .
- Define an augmented weight vector and an augmented feature vector .
- The classifier becomes .
- Note: The slides use this notation implicitly. We will use for the potentially augmented vector and for the potentially augmented input.
- Initialization: Initialize the weight vector . Set a learning rate (often ).
- Cycle through Data: Iterate through the data points repeatedly.
- Check for Misclassification: For the current point , calculate . The point is misclassified if .
- Update Rule: If is misclassified:
- Note on the update: The standard Perceptron update is often written as . If , then and have opposite signs (or ). The term as used in the slide seems potentially incorrect or non-standard. Using directly adjusts in the direction that increases if and decreases if . Sticking precisely to the slide: . (See Page 7 example which uses when , implying was used.)
- Termination: Repeat steps 3-5 until no misclassifications occur during a full cycle through the data.
Perceptron Example (2D - Page 7)
- Illustrates the update rule.
- Before Update: Shows a data point (blue circle, assume ) misclassified by the current boundary defined by (since it’s below the line, ).
- Update: Since , . The update is . This moves the weight vector away from .
- After Update: Shows the new weight vector and the corresponding shifted decision boundary, which is now closer to classifying correctly.
- Final Weights: After convergence, the final weight vector can be expressed as a linear combination of the training data points: , where reflects how often point contributed to an update.
Perceptron Properties
- Convergence Theorem: If the training data is linearly separable, the Perceptron algorithm is guaranteed to converge to a separating hyperplane in a finite number of steps.
- Convergence Speed: Convergence can be slow.
- Solution Quality: The algorithm finds any separating hyperplane, not necessarily the “best” one. The resulting separating line can be very close to the training data points.
- Generalization: A line close to the data points might not generalize well to new, unseen data. We would prefer a solution with a larger margin.
Support Vector Machine (SVM) Classifier
The Concept of Margin
- Problem: For linearly separable data, there can be infinitely many separating hyperplanes. Which one is the best?
- Idea: Choose the hyperplane that maximizes the margin.
- Margin: The margin is the distance between the separating hyperplane and the closest data point(s) from either class. The total width of the “empty” slab around the decision boundary is twice this distance.
- Maximum Margin Solution: The hyperplane that maximizes this margin. This solution is considered the most stable under perturbations of the input data points and often leads to better generalization.
- Support Vectors: The data points that lie exactly on the margin boundaries (closest to the separating hyperplane) are called support vectors. They “support” the hyperplane.
Geometric Intuition (Linearly Separable Case)
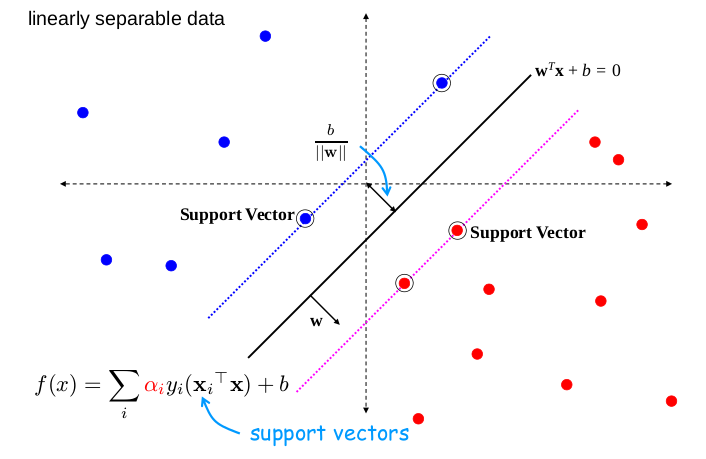
- Decision Boundary: The solid line .
- Margin Boundaries: Two dashed lines parallel to the decision boundary, defined by and .
- Margin Width: The perpendicular distance between the two margin boundaries is .
- Support Vectors: The data points (circled) that lie exactly on the margin boundaries.
- Classifier Form: The final SVM classifier can be expressed as a sum involving only the support vectors: (This form arises from the dual formulation, mentioned later).
Margin Calculation and Normalization (Sketch Derivation)
- Scaling Freedom: The hyperplane is the same as for any constant . We can exploit this to choose a specific normalization for and .
- Canonical Hyperplanes: Choose the scaling such that for the support vectors (positive class) and (negative class) closest to the hyperplane:
- These define the margin boundaries.
- Margin Calculation:
- Consider the vector difference between support vectors on opposite margins: .
- The distance between the margin hyperplanes is the projection of this vector onto the normal vector .
- Margin Width =
- Substitute and : Margin Width = .
Optimization Problem (Hard Margin SVM)
-
Goal: Maximize the margin width .
-
Constraints: All data points must be correctly classified and lie on or outside their respective margin boundary. Using the canonical representation, this means:
- for
- for
- These can be combined into a single constraint: for all .
-
Equivalent Optimization Problem: Maximizing is equivalent to minimizing , which is equivalent to minimizing (the is often added for mathematical convenience in derivation, though the slide omits it). Primal Formulation (Hard Margin):
(Note: Slide 13 uses and , both are valid formulations).
-
Properties:
- This is a Quadratic Programming (QP) problem (quadratic objective, linear constraints).
- It has a unique minimum because the objective function is convex and the constraints define a convex feasible region.
Limitations of Hard Margin and Need for Soft Margin
- Problem 1: Strict Separability: The hard margin SVM requires the data to be perfectly linearly separable. It cannot handle data that is not linearly separable (as in page 3 bottom examples).
- Problem 2: Sensitivity to Outliers: Even if data is separable, a single outlier might force the margin to be very narrow, potentially leading to a less robust classifier (as hinted in page 14 top example).
- Trade-off: Sometimes, allowing a few points to be misclassified or lie within the margin might lead to a much larger margin and better overall generalization (as suggested in page 14 bottom example).
Soft Margin SVM: Slack Variables
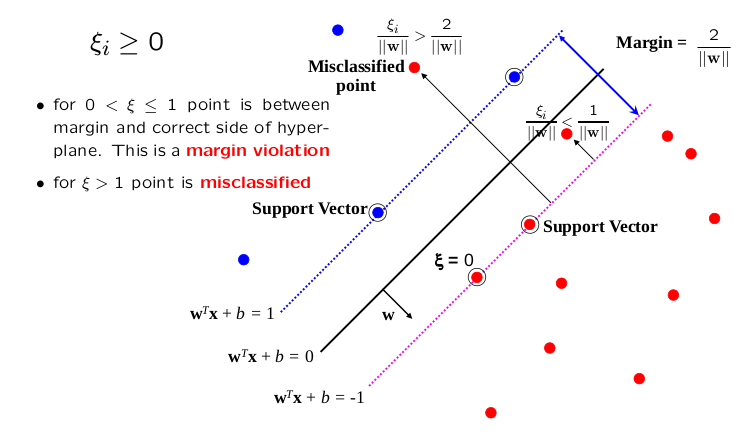
- Idea: Introduce slack variables, denoted by (Greek letter xi), for each data point .
- Purpose: Allow individual points to violate the margin constraint .
- Modified Constraint:
- Slack Variable Constraint: We require .
- Interpretation of (Page 15):
- : Point is correctly classified and is on or outside the margin boundary (satisfies the hard margin constraint).
- : Point is correctly classified () but lies inside the margin (). This is a margin violation.
- : Point is misclassified ().
- Penalty: We want to minimize the total amount of slack introduced.
Optimization Problem (Soft Margin SVM)
-
Objective: Minimize a combination of the classifier complexity (related to margin width) and the total slack. Primal Formulation (Soft Margin):
$$\quad y_i (\mathbf{w}^T \mathbf{x}_i + b) \ge 1 - \xi_i, \quad \text{for } i = 1, \dots, N $$$$ \quad \xi_i \ge 0, \quad \text{for } i = 1, \dots, N
- $\boldsymbol{\xi} = (\xi_1, \dots, \xi_N)$ is the vector of slack variables. - $C \ge 0$ is the **regularization parameter**. -
Role of Regularization Parameter :
- Controls the trade-off between maximizing the margin (minimizing ) and minimizing the classification/margin errors (minimizing ).
- Small : Lower penalty on slack variables (). Allows more points to violate the margin (larger ) in favor of achieving a wider margin (smaller ). Can lead to simpler models, potentially underfitting if too small.
- Large : Higher penalty on slack variables. Forces the optimizer to minimize margin violations. Behaves more like the hard margin SVM. Can lead to narrower margins and potentially overfitting if too large.
- : Corresponds to the hard margin SVM (no slack allowed).
-
Properties:
- Still a Quadratic Programming problem.
- Has a unique minimum.
- is a hyperparameter that needs to be chosen (e.g., via cross-validation).
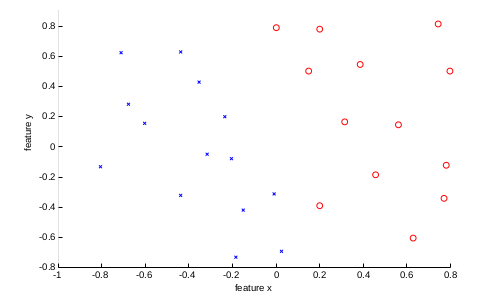
Examples of Varying C (Pages 17-19)
- Data: 2D data that is linearly separable but requires a narrow margin for perfect separation (Page 17).
- Case 1: (Hard Margin - Page 18)
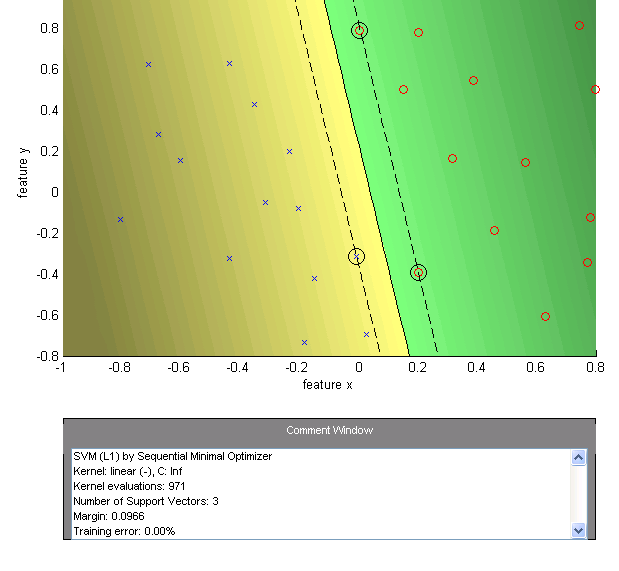
- Finds the separating hyperplane with the largest margin while correctly classifying all points.
- Result: Margin = 0.0966, Training error = 0.00%, 3 Support Vectors. The margin is very narrow.
- Case 2: (Soft Margin - Page 19)
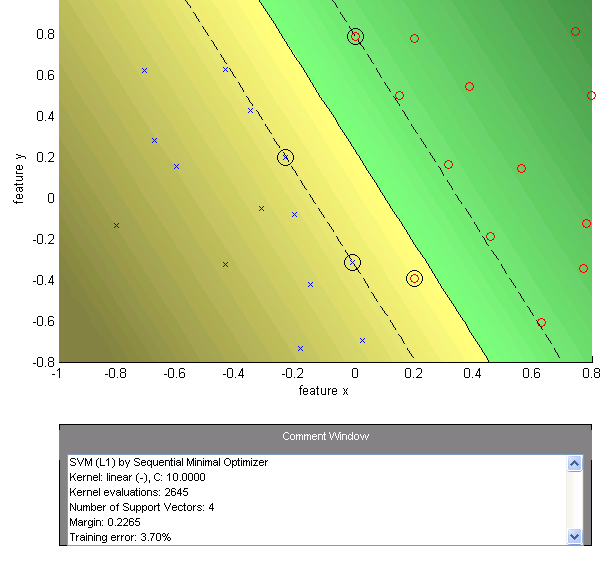
- Allows some margin violation to potentially achieve a wider margin.
- Result: Margin = 0.2265, Training error = 3.70% (one point is likely inside the margin or misclassified), 4 Support Vectors. The margin is significantly wider.
Application: Pedestrian Detection in Computer Vision
Objective
- Detect (localize) standing humans in images.
Approach: Sliding Window Classifier
- Define a window of a fixed size.
- Slide this window across the image at different positions and scales.
- For each window, classify whether it contains the object of interest (a pedestrian) or not.
- This reduces object detection to a binary classification problem.